
[JBHI 2022]A Pseudo Label-Wise Attention Network for Automatic ICD Coding
计算机-人工智能-伪注意力多标签ICD分类

论文代码:https://github.com/CSUBioGroup/LD-PLAM
目录
2.3. Problem Statement and Notations
2.4.2. Representation of ICD Codes
2.4.3. Calculation of the Similarity Between EMR Vectors and ICD Vectors
2.4.4. Comparison Between Pseudo Label-Wise Attention and Label-Wise Attention
2.5.4. Comparison With Other Methods
2.6.1. Prediction of New ICD Codes
2.6.2. Effect of Label Frequency
1. 心得
(1)很标准的一篇论文,看完有种切切实实该发这个期刊不高也不低的感觉
(2)实验比模型更ok
2. 论文逐段精读
2.1. Abstract
①为了减少计算开支,作者使用伪标签注意力,对相似的ICD编码用同样的注意力
②图片摘要:
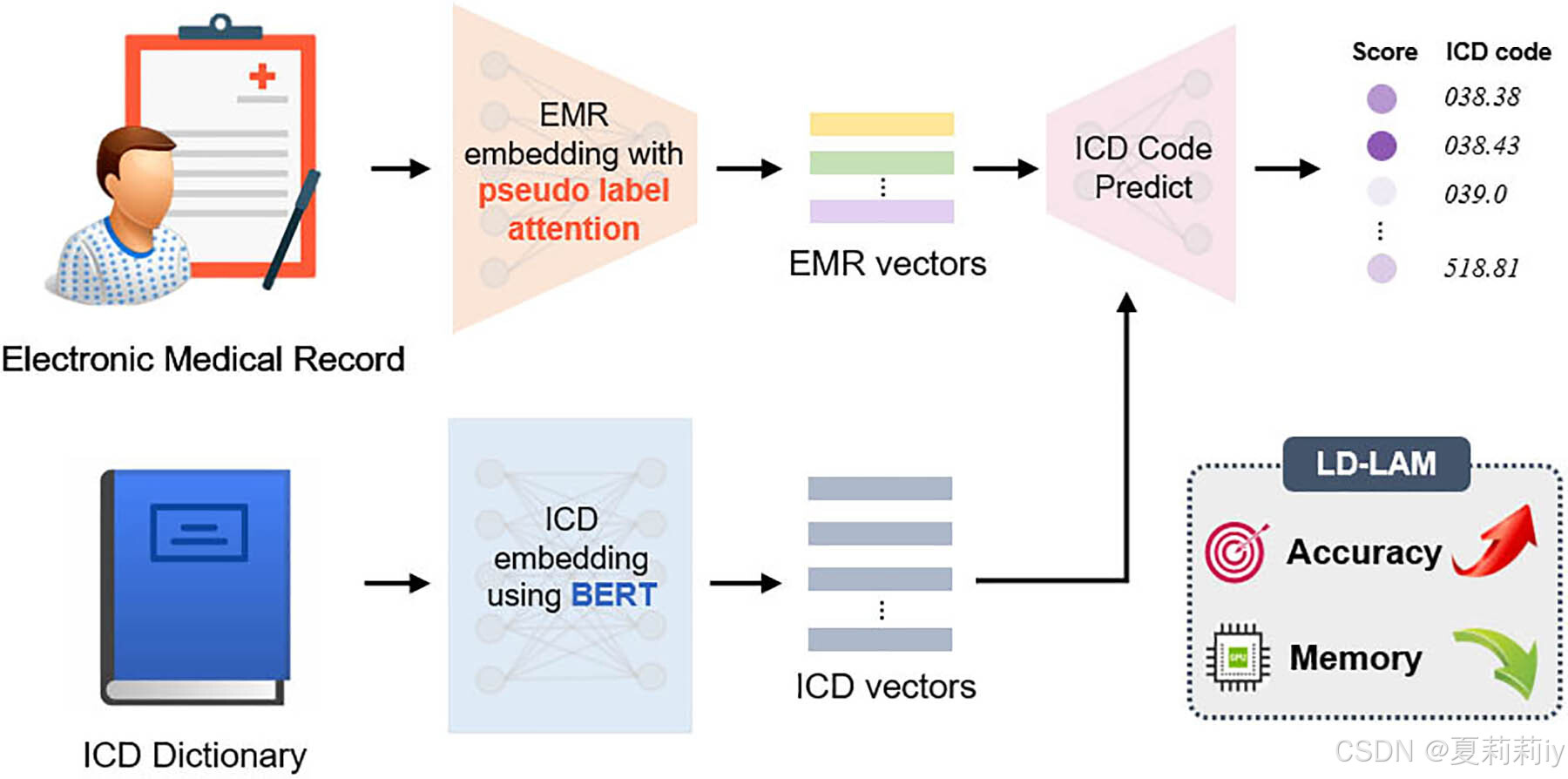
2.2. Introduction
①挑战:总类别多单个体标签少(其实也多),代码预测频率分布不均,预测新样本或零样本分类
②现有工作爱为每个ICD代码都分配一个注意力权重,作者认为这是多余的。作者倾向为每个分支分配一个权重
2.3. Problem Statement and Notations
①临床记录:,其中
是临床记录总长度
②预测目标:,其中
是ICD编码的总数,数值只会有0和1
③符号:

2.4. Methodology
①模型框架:
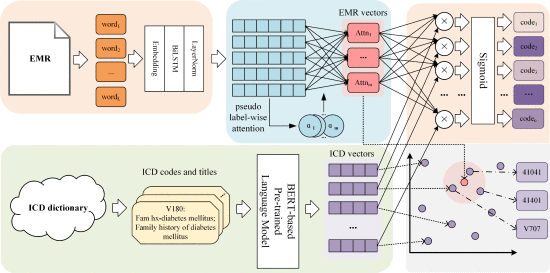
2.4.1. Representation of EMRs
①电子病历 (Electronic Medical Records,EMR)处理:填充短病历长度,截断超出长度。但不是直接截断,要把不重要的单词删除。⭐使用术语频率-逆文档频率 (TF-IDF) 来衡量单词的重要性,它定义为术语频率和逆文档频率的乘积。(酱紫麻烦?)
②训练EMR:skip-gram和双向LSTM
③伪标签注意力:
其中是双向LSTM的输出,
是非线性层。(这个东西好奇怪)
2.4.2. Representation of ICD Codes
①作者将ICD整理为“ICD代码:ICD标题(描述)”
②使用RoBERTa对ICD集合进行映射:
2.4.3. Calculation of the Similarity Between EMR Vectors and ICD Vectors
①计算EMR和ICD嵌入的相似性:
2.4.4. Comparison Between Pseudo Label-Wise Attention and Label-Wise Attention
①时间复杂度:

②标签注意力和伪标签注意力的区别:
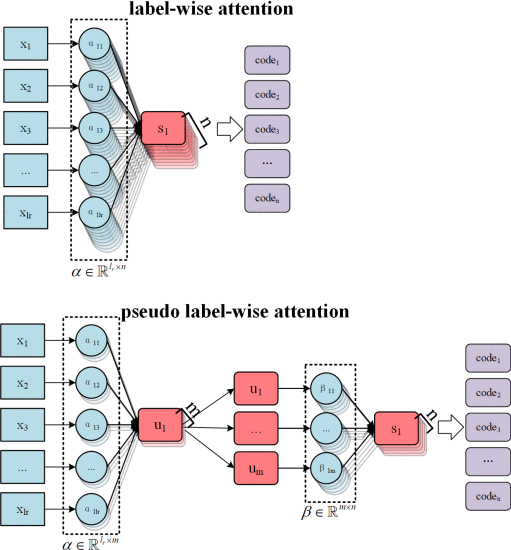
2.5. Experiments
2.5.1. Datasets
①数据集统计:
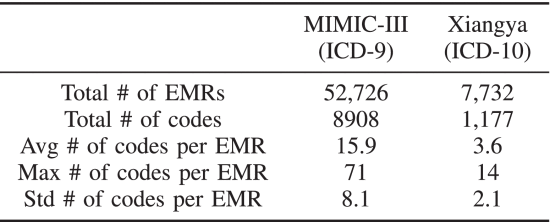
其中MIMIC也被分为MIMIC-III full和MIMIC-III 50,湘雅也同样被分为这两种
2.5.2. Baselines
①列举一些基线
2.5.3. Training Details
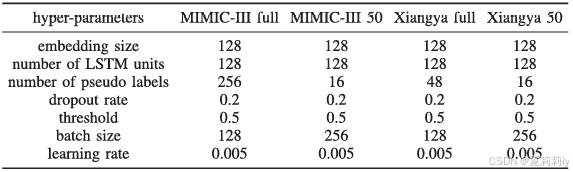
①LSTM单元数量实验:{64,128,256}
②伪标签数量:{16,32,64,128,256,384,512}
③批次大小:{64,128,256}
④学习率:{0.0003,0.001,0.005,0.01}
⑤网格搜索表:
2.5.4. Comparison With Other Methods
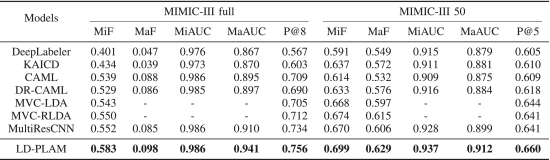
①MIMIC数据集的表现:
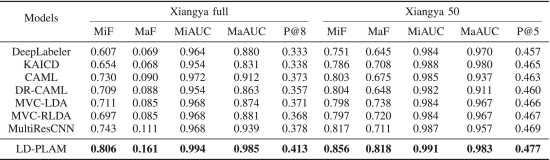
②湘雅数据集表现:
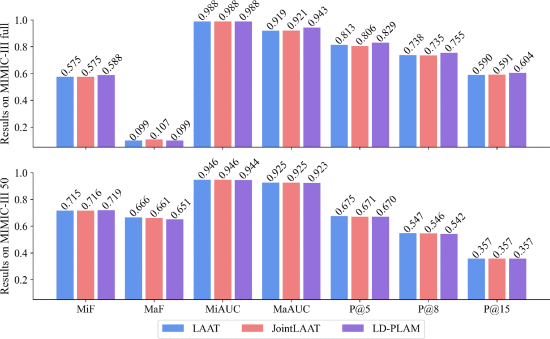
③训练策略消融:
2.5.5. Memory Analysis
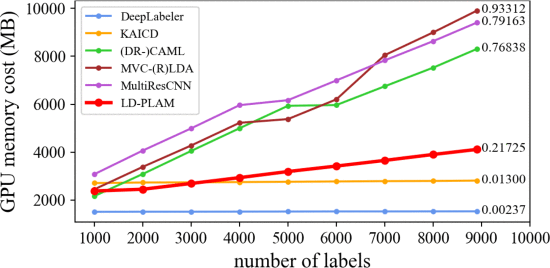
①不同标签数量下的内存占用:
2.5.6. Ablative Analysis
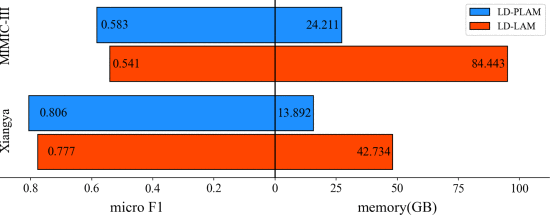
①标签注意力和伪标签注意力的内存占用和性能:
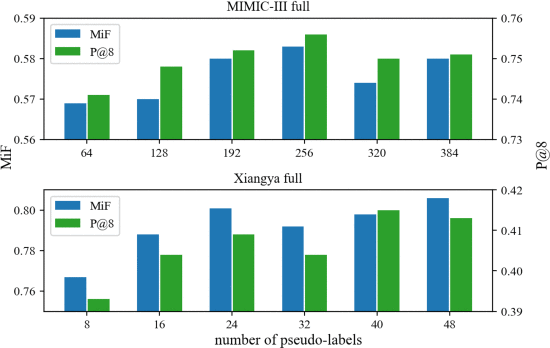
②伪标签数量对性能的影响:
③ICD标题的消融:

2.6. Discussion
2.6.1. Prediction of New ICD Codes
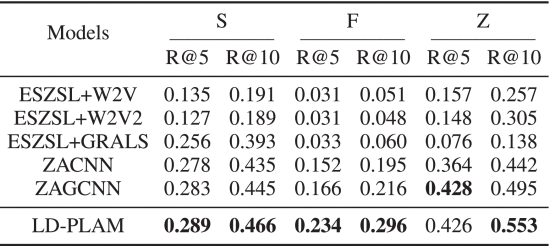
①将ICD代码分为三组:S(可见ICD代码,训练出现五次以上)、F(少量ICD代码,出现一到五次)和Z组(零样本ICD代码,未出现过)
②这些训练用例的分类结果:
2.6.2. Effect of Label Frequency
①模型对不同频率标签的预测AUC:
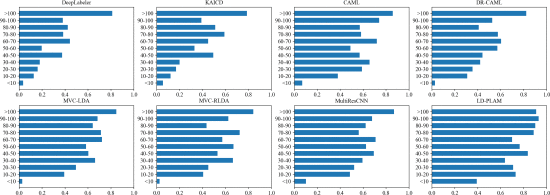
2.6.3. Model Interpretability
①⭐每个ICD编码对应的四个最关键的词:
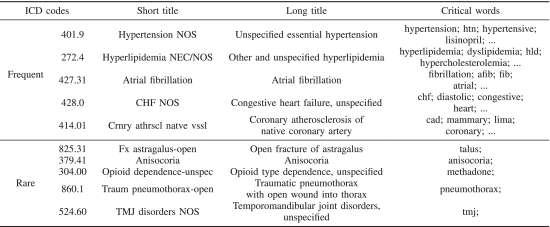
2.6.4. Case Study
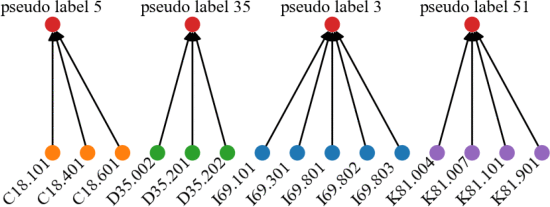
①伪注意力集成:
2.7. Conclusion
~

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)