
人工智能开发工具全景指南:从编码辅助到模型部署的全链路实践
本文系统梳理了AI开发全流程中的核心工具链,涵盖编码辅助、数据标注、模型训练、部署与监控五大环节。在编码环节,GitHub Copilot等智能工具显著提升开发效率;数据标注部分重点介绍了LabelStudio等开源平台的使用方法;模型训练章节对比了MLflow和Kubeflow等平台的适用场景;部署环节详细解析了ONNXRuntime等推理引擎的优化技巧;监控部分则展示了数据漂移检测和服务健康监
人工智能技术的飞速发展催生了品类繁多的开发工具生态,这些工具正在深刻改变开发者的工作方式,显著提升 AI 项目的开发效率与质量。本文将系统梳理 AI 开发全链路中的核心工具,涵盖智能编码辅助、数据处理与标注、模型训练与优化、部署与监控四大环节,并通过代码示例、Mermaid 流程图、Prompt 工程案例和对比图表,为读者提供一份兼具理论深度与实践价值的工具使用指南。
一、智能编码辅助工具:AI 驱动的开发效率革命
智能编码工具利用大规模语言模型(LLM)理解代码上下文,为开发者提供实时的代码补全、函数生成、错误修复及文档生成功能。这类工具已成为 AI 时代开发者的标配,其中GitHub Copilot、Tabnine和Amazon CodeWhisperer是当前市场的主流产品。
1.1 GitHub Copilot:最广泛使用的 AI 编码助手
GitHub Copilot 由 GitHub 与 OpenAI 联合开发,基于 GPT 系列模型优化训练,支持数十种编程语言和主流 IDE(VS Code、JetBrains 全家桶、Neovim 等)。其核心能力在于将自然语言描述转化为代码,并能根据现有代码风格进行上下文感知补全。
1.1.1 核心功能与使用场景
- 实时代码补全:在输入变量名、函数定义或注释时,自动生成后续代码
- 自然语言转代码:通过注释描述功能需求,生成完整函数或类
- 代码优化与重构:识别冗余代码,提供简化或性能优化建议
- 单元测试生成:为现有函数自动生成测试用例
- 多语言支持:从 Python、JavaScript 到 Rust、Go 均有出色表现
1.1.2 实践案例:用 Copilot 构建 Python 数据处理函数
场景:需要一个函数,接收 Pandas DataFrame 和列名,返回该列的缺失值统计(数量、比例)及填充建议。
Prompt(注释形式):
python
运行
import pandas as pd
import numpy as np
def analyze_missing_values(df: pd.DataFrame, column: str) -> dict:
"""
分析DataFrame中指定列的缺失值情况
参数:
df: 输入的Pandas DataFrame
column: 需要分析的列名
返回:
包含以下键的字典:
'missing_count': 缺失值数量
'missing_ratio': 缺失值比例(0-1)
'data_type': 列的数据类型
'suggestion': 根据数据类型给出的填充建议(如均值、中位数、众数、0等)
"""
# 实现这个函数
Copilot 自动生成的代码:
python
运行
import pandas as pd
import numpy as np
def analyze_missing_values(df: pd.DataFrame, column: str) -> dict:
"""
分析DataFrame中指定列的缺失值情况
参数:
df: 输入的Pandas DataFrame
column: 需要分析的列名
返回:
包含以下键的字典:
'missing_count': 缺失值数量
'missing_ratio': 缺失值比例(0-1)
'data_type': 列的数据类型
'suggestion': 根据数据类型给出的填充建议(如均值、中位数、众数、0等)
"""
# 检查列是否存在于DataFrame中
if column not in df.columns:
raise ValueError(f"列名 '{column}' 不存在于DataFrame中")
# 计算缺失值数量和比例
missing_count = df[column].isnull().sum()
total_count = len(df)
missing_ratio = missing_count / total_count if total_count > 0 else 0
# 获取数据类型
data_type = str(df[column].dtype)
# 根据数据类型给出填充建议
suggestion = ""
if pd.api.types.is_numeric_dtype(df[column]):
# 数值型数据:检查是否有异常值,决定用均值还是中位数
q1 = df[column].quantile(0.25)
q3 = df[column].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
has_outliers = ((df[column] < lower_bound) | (df[column] > upper_bound)).any()
if has_outliers:
suggestion = f"存在异常值,建议使用中位数填充:{df[column].median():.2f}"
else:
suggestion = f"无明显异常值,建议使用均值填充:{df[column].mean():.2f}"
elif pd.api.types.is_categorical_dtype(df[column]):
# 分类数据:使用众数填充
mode_val = df[column].mode().iloc[0] if not df[column].mode().empty else None
suggestion = f"分类数据,建议使用众数填充:{mode_val}"
elif pd.api.types.is_datetime64_any_dtype(df[column]):
# 日期时间数据:使用前后向填充或特定日期
suggestion = f"日期时间数据,建议使用前向填充(ffill)或后向填充(bfill)"
else:
# 其他类型(如字符串):使用众数或特定字符串
mode_val = df[column].mode().iloc[0] if not df[column].mode().empty else "Unknown"
suggestion = f"字符串/其他类型,建议使用众数填充:{mode_val}"
return {
'missing_count': missing_count,
'missing_ratio': round(missing_ratio, 4),
'data_type': data_type,
'suggestion': suggestion
}
# 测试代码
if __name__ == "__main__":
# 创建测试DataFrame
data = {
'age': [25, 30, np.nan, 35, 40, np.nan, 45, 50, 55, np.nan],
'gender': ['male', 'female', 'male', np.nan, 'female', 'male', np.nan, 'female', 'male', 'female'],
'income': [50000, 60000, 70000, 1000000, 80000, 90000, 110000, 120000, 130000, np.nan],
'join_date': pd.date_range('2020-01-01', periods=10, freq='M')
}
df = pd.DataFrame(data)
# 分析各列缺失值
for col in df.columns:
result = analyze_missing_values(df, col)
print(f"\n=== {col} 列缺失值分析 ===")
print(f"缺失值数量: {result['missing_count']}")
print(f"缺失值比例: {result['missing_ratio']:.2%}")
print(f"数据类型: {result['data_type']}")
print(f"填充建议: {result['suggestion']}")
代码说明:Copilot 不仅实现了基础的缺失值统计功能,还额外添加了列存在性检查、异常值检测(IQR 方法)和基于数据类型的智能填充建议,甚至自动生成了测试代码。这展示了其理解复杂需求并生成高质量代码的能力。
1.2 主流智能编码工具对比
| 工具 | 开发者 | 基础模型 | 支持语言 / IDE | 核心特点 | 定价模式 |
|---|---|---|---|---|---|
| GitHub Copilot | GitHub + OpenAI | GPT-4/GPT-3.5 | 50 + 语言,VS Code、JetBrains、Neovim 等 | 上下文感知强,自然语言转代码出色 | 个人版 $19.99 / 月,企业版按用户收费 |
| Amazon CodeWhisperer | AWS | 自研大语言模型 | 15 + 语言,VS Code、JetBrains、Cloud9 | 与 AWS 服务深度集成,免费 tier 可用 | 免费(基础版),专业版 $19 / 月 |
| Tabnine | Tabnine | 自研 + 开源模型 | 20 + 语言,主流 IDE 全覆盖 | 支持团队私有模型训练,离线使用 | 免费(基础版),专业版 $12 / 月 |
| CodeLlama | Meta | CodeLlama 系列 | 多种语言,需自行部署 | 开源免费,支持本地运行,可微调 | 免费(开源) |
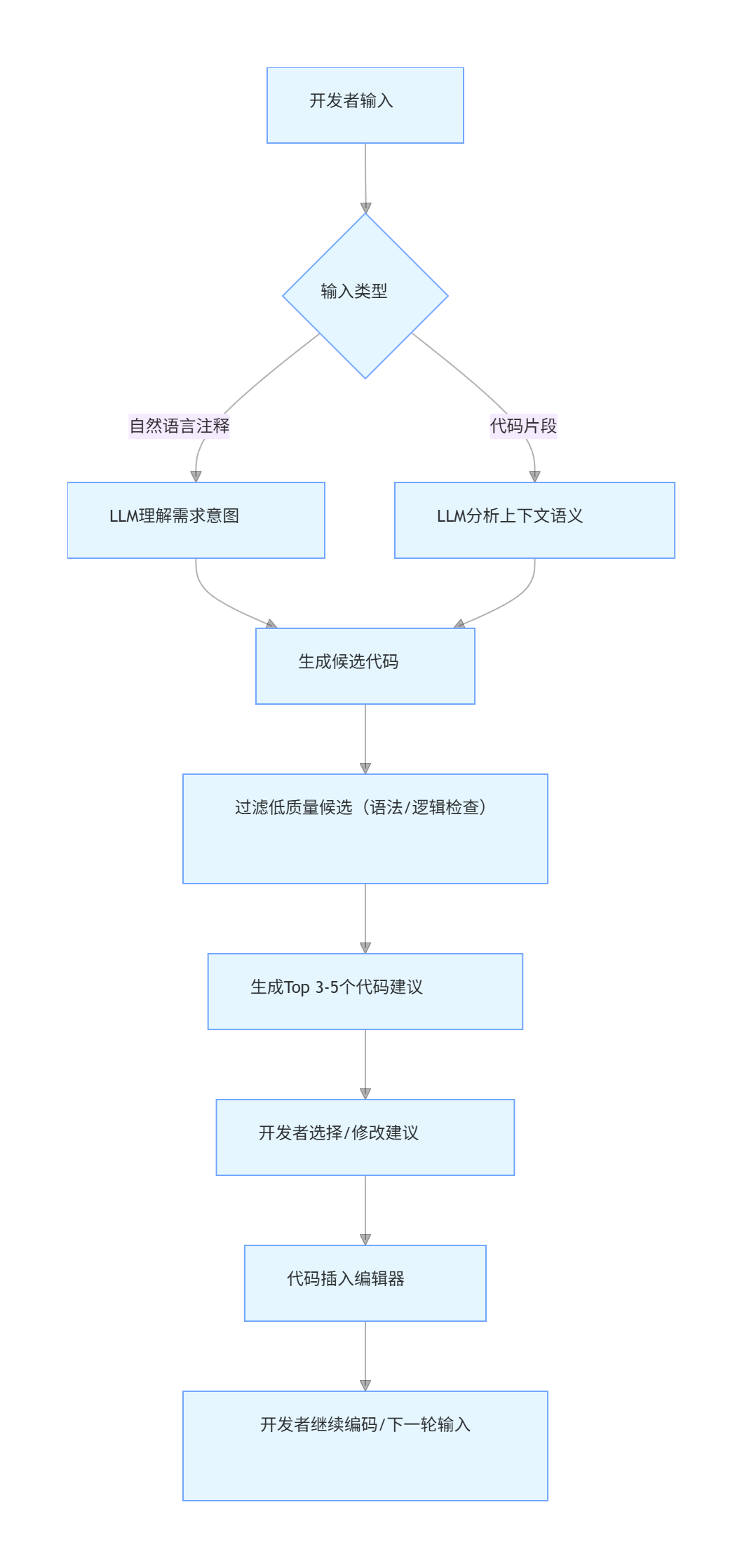
1.3 智能编码工具工作流程
flowchart TD
A[开发者输入] --> B{输入类型}
B -->|自然语言注释| C[LLM理解需求意图]
B -->|代码片段| D[LLM分析上下文语义]
C --> E[生成候选代码]
D --> E
E --> F[过滤低质量候选(语法/逻辑检查)]
F --> G[生成Top 3-5个代码建议]
G --> H[开发者选择/修改建议]
H --> I[代码插入编辑器]
I --> J[开发者继续编码/下一轮输入]
二、数据标注工具:高质量 AI 模型的基石
数据标注是 AI 开发中的关键环节,其质量直接决定模型性能。数据标注工具通过可视化界面和自动化辅助功能,帮助标注员高效完成图像、文本、音频、视频等数据的标注工作。
2.1 数据标注工具分类与典型场景
根据数据类型,标注工具可分为以下几类:
| 数据类型 | 标注任务 | 典型工具 | 应用场景 |
|---|---|---|---|
| 图像 | 分类、目标检测(Bounding Box)、语义分割、实例分割、关键点检测 | LabelImg、LabelMe、VGG Image Annotator(VIA)、CVAT | 自动驾驶(行人 / 车辆检测)、人脸识别、医学影像分析 |
| 文本 | 分类、命名实体识别(NER)、情感分析、文本摘要、问答配对 | Prodigy、LabelStudio、TextAnnotationTool | 新闻分类、智能客服(意图识别)、舆情分析 |
| 音频 | 语音转文字(ASR)、情感识别、说话人分离 | Audacity(辅助)、LabelStudio、Amazon Transcribe | 智能音箱、语音助手、电话录音分析 |
| 视频 | 时序目标跟踪、行为识别、帧级标注 | CVAT、LabelStudio、AWS Ground Truth | 安防监控(异常行为检测)、动作捕捉 |
2.2 LabelStudio:全功能开源标注平台
LabelStudio 是当前最流行的开源数据标注工具,支持几乎所有数据类型和标注任务,具有高度可扩展性和自定义能力。其核心优势在于:
- 开源免费,可本地部署确保数据安全
- 支持团队协作与标注任务管理
- 提供 REST API 和 SDK,便于与 AI 流水线集成
- 可自定义标注界面和标签体系
2.2.1 LabelStudio 安装与启动
bash
# 使用pip安装
pip install label-studio
# 启动LabelStudio服务(默认端口8080)
label-studio start
# 或指定端口和项目名称
label-studio start my_annotation_project --port 8081
启动后访问http://localhost:8080,创建管理员账号即可开始使用。
2.2.2 实践案例:图像目标检测标注(Bounding Box)
步骤 1:创建项目
- 点击 "Create Project",输入项目名称(如 "自动驾驶车辆检测")
- 选择标注任务类型:"Object Detection with Bounding Boxes"
- 定义标签集:添加 "car"、"pedestrian"、"traffic_light" 三个标签
步骤 2:导入数据
- 支持本地文件上传、URL 导入或连接云存储(S3、GCS)
- 本次导入 100 张城市道路场景图片
步骤 3:标注界面与操作LabelStudio 提供直观的标注界面,主要功能包括:
- 左侧:标签列表
- 中间:图像预览区
- 右侧:标注历史与属性编辑
- 快捷键:
w(创建框)、d(下一张)、a(上一张)、del(删除标注)
标注操作流程:
- 选中左侧 "car" 标签
- 在图像中拖拽鼠标创建 Bounding Box 包围车辆
- 重复步骤 1-2 标注所有车辆、行人和交通灯
- 点击 "Submit" 提交当前图像标注结果
2.2.3 标注结果导出与格式转换
标注完成后,可导出多种格式的结果,满足不同训练框架需求:
| 导出格式 | 适用框架 / 工具 | 特点 |
|---|---|---|
| JSON | 通用格式,可自定义解析 | 包含完整标注信息和元数据 |
| COCO | YOLO、Mask R-CNN 等 | 目标检测 / 分割领域标准格式 |
| Pascal VOC | Faster R-CNN、SSD 等 | 传统目标检测常用格式 |
| YOLO | YOLO 系列模型 | 简化的 txt 格式,每行一个目标 |
导出 COCO 格式示例代码:
python
运行
import json
import os
from label_studio_sdk import Client
# 连接LabelStudio服务
ls = Client(url='http://localhost:8080', api_key='YOUR_API_KEY')
# 获取项目
project = ls.get_project(1) # 项目ID从界面URL获取
# 导出COCO格式标注
export_data = project.export_tasks(format='COCO')
# 保存到文件
with open('annotations_coco.json', 'w') as f:
json.dump(export_data, f, indent=2)
print(f"成功导出 {len(export_data['annotations'])} 个标注,涵盖 {len(export_data['images'])} 张图片")
2.3 自动化标注与 AI 辅助标注
为提升标注效率,现代工具普遍集成 AI 辅助功能,通过预训练模型自动生成初始标注,再由人工审核修正。
2.3.1 LabelStudio AI 辅助标注配置
以图像目标检测为例,配置 YOLOv8 作为辅助标注模型:
- 在项目设置中启用 "Machine Learning"
- 选择 "Object Detection" 模型类型
- 输入模型 API 地址(如本地部署的 YOLOv8 服务)
- 设置置信度阈值(如 0.5,仅保留高置信度预测结果)
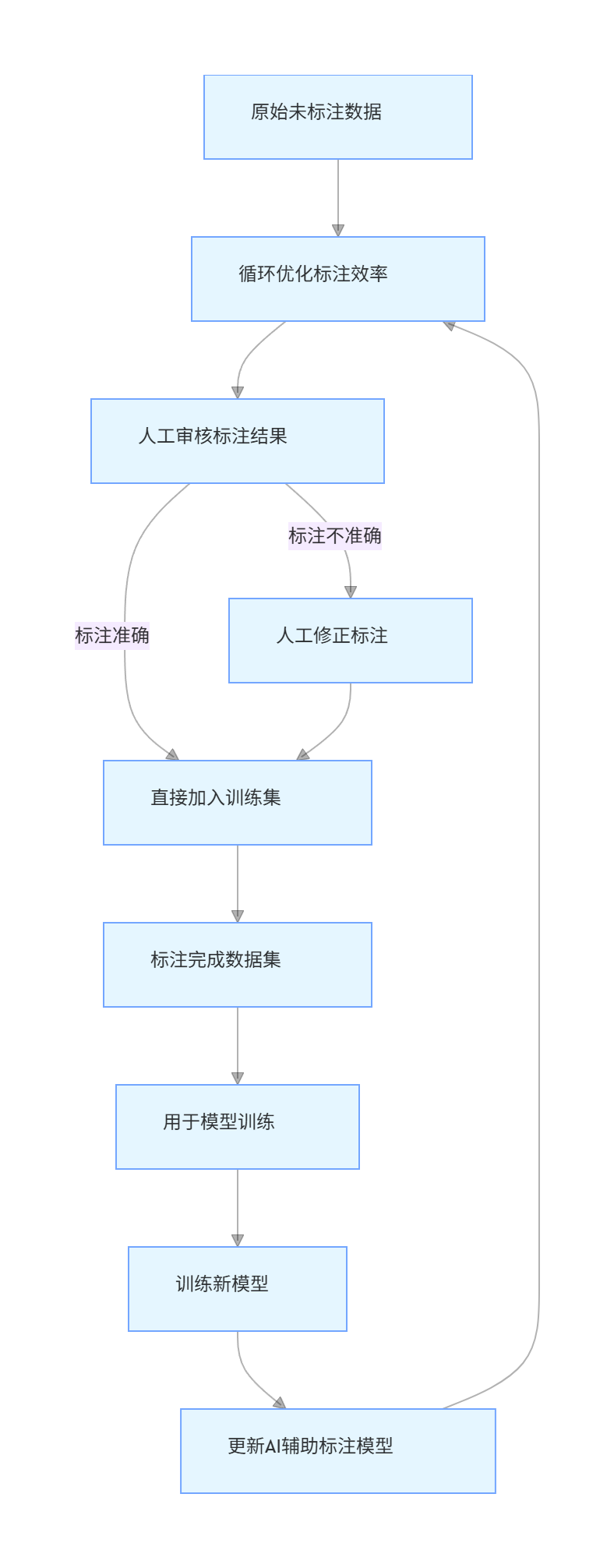
2.3.2 自动化标注工作流程
flowchart TD
A[原始未标注数据] --> B[AI辅助模型生成初始标注]
B --> C[人工审核标注结果]
C -->|标注准确| D[直接加入训练集]
C -->|标注不准确| E[人工修正标注]
E --> D
D --> F[标注完成数据集]
F --> G[用于模型训练]
G --> H[训练新模型]
H --> I[更新AI辅助标注模型]
I --> B[循环优化标注效率]
三、模型训练平台:从实验到生产的桥梁
模型训练平台提供了模型开发、训练、优化和管理的全流程支持,解决了传统开发中环境不一致、资源调度复杂、实验可复现性差等问题。主流平台可分为云原生平台(如 AWS SageMaker、Google AI Platform)和开源本地平台(如 MLflow、Kubeflow)。
3.1 MLflow:机器学习生命周期管理工具
MLflow 是 Databricks 开源的 ML 生命周期管理平台,核心功能包括实验跟踪、模型管理、项目打包和模型部署,支持所有主流 ML 框架(TensorFlow、PyTorch、Scikit-learn 等)。
3.1.1 MLflow 核心组件
- MLflow Tracking:记录实验参数、指标、 artifacts(模型文件、日志等)
- MLflow Projects:将 ML 代码打包为可复现的项目格式
- MLflow Models:统一模型格式,支持跨平台部署
- MLflow Registry:模型版本管理、阶段控制(Staging/Production)
3.1.2 实践案例:用 MLflow 跟踪 Scikit-learn 分类实验
场景:基于鸢尾花数据集,比较不同分类算法(逻辑回归、随机森林、SVM)的性能,并通过 MLflow 记录实验结果。
代码实现:
python
运行
import mlflow
import mlflow.sklearn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import numpy as np
# 1. 初始化MLflow实验(指定实验名称,不存在则自动创建)
mlflow.set_experiment("Iris Classification Comparison")
# 2. 加载数据并预处理(鸢尾花数据集,经典多分类任务)
iris = load_iris()
X = iris.data # 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y = iris.target # 标签:0=山鸢尾,1=变色鸢尾,2=维吉尼亚鸢尾
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42 # 80%训练集,20%测试集
)
# 3. 定义模型训练与评估函数(集成MLflow跟踪逻辑)
def train_evaluate_model(model_name, model, params):
"""
训练模型并使用MLflow跟踪实验全流程
:param model_name: 模型名称(如"Logistic Regression")
:param model: 未训练的Scikit-learn模型实例
:param params: 模型训练参数(字典形式)
:return: 训练后的模型
"""
# 启动MLflow运行(每个模型对应一个独立运行记录)
with mlflow.start_run(run_name=model_name):
# 3.1 记录实验参数(模型超参数、数据处理参数等)
mlflow.log_params(params)
# 额外记录数据划分参数(确保实验可复现)
mlflow.log_param("test_size", 0.2)
mlflow.log_param("random_state", 42)
# 3.2 训练模型
model.fit(X_train, y_train)
# 3.3 模型预测(训练集+测试集,用于评估过拟合情况)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
# 3.4 计算评估指标(多分类任务使用macro平均)
metrics = {
"train_accuracy": accuracy_score(y_train, y_train_pred),
"test_accuracy": accuracy_score(y_test, y_test_pred),
"train_precision": precision_score(y_train, y_train_pred, average="macro"),
"test_precision": precision_score(y_test, y_test_pred, average="macro"),
"train_recall": recall_score(y_train, y_train_pred, average="macro"),
"test_recall": recall_score(y_test, y_test_pred, average="macro"),
"train_f1": f1_score(y_train, y_train_pred, average="macro"),
"test_f1": f1_score(y_test, y_test_pred, average="macro")
}
# 3.5 记录评估指标(MLflow支持实时查看指标趋势)
mlflow.log_metrics(metrics)
# 3.6 记录模型 artifacts(保存训练后的模型,用于后续部署)
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="trained_model", # 模型在 artifacts 中的路径
registered_model_name=f"{model_name}_Iris" # 注册到模型仓库的名称
)
# 3.7 记录额外 artifacts(如数据集描述、模型可视化图表等)
# 示例:保存数据集特征名称到文本文件
feature_names = iris.feature_names
with open("feature_names.txt", "w") as f:
f.write("\n".join(feature_names))
mlflow.log_artifact("feature_names.txt") # 将文件添加到 artifacts
# 打印实验结果(便于本地调试)
print(f"=== {model_name} 实验结果 ===")
for metric_name, metric_value in metrics.items():
print(f"{metric_name}: {metric_value:.4f}")
print(f"MLflow Run ID: {mlflow.active_run().info.run_id}\n")
return model
# 4. 定义待对比的模型与参数(构建实验矩阵)
models_to_train = [
# 逻辑回归
{
"model_name": "Logistic Regression",
"model_class": LogisticRegression,
"params": {
"max_iter": 200, # 增加迭代次数确保收敛
"C": 1.0, # 正则化强度(越小正则化越强)
"solver": "liblinear" # 适用于小数据集的求解器
}
},
# 随机森林
{
"model_name": "Random Forest",
"model_class": RandomForestClassifier,
"params": {
"n_estimators": 100, # 决策树数量
"max_depth": 5, # 树的最大深度(防止过拟合)
"random_state": 42
}
},
# 支持向量机
{
"model_name": "Support Vector Machine",
"model_class": SVC,
"params": {
"kernel": "rbf", # 径向基核函数(处理非线性关系)
"C": 1.0,
"gamma": "scale", # 自动缩放核系数
"random_state": 42
}
}
]
# 5. 批量运行实验(训练所有模型并跟踪)
trained_models = []
for model_config in models_to_train:
model = model_config["model_class"](**model_config["params"])
trained_model = train_evaluate_model(
model_name=model_config["model_name"],
model=model,
params=model_config["params"]
)
trained_models.append(trained_model)
# 6. 启动MLflow UI(查看实验结果)
# 终端执行命令:mlflow ui --port 5000
# 访问地址:http://localhost:5000
3.1.3 MLflow 实验结果查看与分析
-
启动 MLflow UI:在终端执行
mlflow ui --port 5000,访问http://localhost:5000即可看到实验 dashboard。 -
核心查看维度:
- 实验对比:在「Iris Classification Comparison」实验下,可看到 3 个模型的运行记录,支持按「test_accuracy」排序,快速定位最优模型(通常随机森林表现更优)。
- 参数与指标关联:点击某条运行记录,可查看该模型的所有参数(如随机森林的
n_estimators=100)、指标趋势(如训练 / 测试准确率对比,判断是否过拟合)。 - Artifacts 下载:在「Artifacts」标签页,可下载训练好的模型(
trained_model文件夹)、特征名称文件(feature_names.txt),直接用于后续部署。
-
模型注册与版本管理:由于代码中使用了
registered_model_name参数,训练后的模型会自动注册到「Models」仓库。可在 UI 中将最优模型(如随机森林)从「Staging」阶段提升到「Production」阶段,明确生产环境使用的模型版本。
3.2 Kubeflow: Kubernetes 原生的大规模 ML 平台
对于企业级大规模机器学习场景(如分布式训练、多团队协作、定时任务调度),Kubeflow 是当前主流选择。它基于 Kubernetes 构建,将 ML 工作流(数据处理、模型训练、部署)封装为可编排的 Pipeline,实现端到端自动化。
3.2.1 Kubeflow 核心组件
| 组件 | 功能 | 应用场景 |
|---|---|---|
| Kubeflow Pipelines | 定义、部署和管理 ML 工作流,将步骤封装为容器化组件 | 构建可复现的端到端 ML 流水线(如 “数据清洗→特征工程→模型训练→评估→部署”) |
| TFJob/PyTorchJob | 为 TensorFlow/PyTorch 提供分布式训练支持,自动调度 GPU/TPU 资源 | 大规模模型训练(如 BERT、ResNet),需要多 GPU 节点并行计算 |
| KFServing | 模型部署标准化组件,支持 TensorFlow Serving、TorchServe 等,提供 REST/gRPC 接口 | 生产环境模型部署,支持 A/B 测试、流量控制、模型版本切换 |
| Feast | 特征存储组件,统一管理特征数据,支持离线特征生成与在线特征服务 | 解决 “特征孤岛” 问题,确保训练与推理使用一致的特征计算逻辑 |
3.2.2 实践案例:用 Kubeflow Pipeline 构建鸢尾花分类流水线
以下是一个简化的 Kubeflow Pipeline 定义,包含 “数据加载→特征标准化→模型训练→模型评估”4 个步骤,使用 Python SDK 编写:
python
运行
import kfp
from kfp import dsl
from kfp.components import create_component_from_func, func_to_container_op
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import numpy as np
# 1. 定义Pipeline的各个组件(每个组件对应一个函数,将被容器化)
# 组件1:加载并分割数据
def load_data(test_size: float = 0.2, random_state: int = 42) -> tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]:
"""加载鸢尾花数据集并划分为训练集/测试集"""
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state
)
# 返回numpy数组(Kubeflow支持基本数据类型和numpy类型的传递)
return X_train, X_test, y_train, y_test
# 组件2:特征标准化(消除量纲影响)
def standardize_features(X_train: np.ndarray, X_test: np.ndarray) -> tuple[np.ndarray, np.ndarray]:
"""对训练集特征进行标准化,并用相同的缩放器处理测试集"""
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 可选:将scaler保存为artifact(用于后续推理)
import joblib
joblib.dump(scaler, "/mnt/scaler.pkl") # /mnt为Kubeflow默认挂载目录
return X_train_scaled, X_test_scaled
# 组件3:训练随机森林模型
def train_model(
X_train: np.ndarray, y_train: np.ndarray,
n_estimators: int = 100, max_depth: int = 5
) -> RandomForestClassifier:
"""训练随机森林模型并保存"""
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
model.fit(X_train, y_train)
# 保存模型到挂载目录
import joblib
joblib.dump(model, "/mnt/rf_model.pkl")
return model
# 组件4:模型评估并输出准确率
def evaluate_model(
model: RandomForestClassifier, X_test: np.ndarray, y_test: np.ndarray
) -> float:
"""评估模型在测试集上的准确率"""
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Test Accuracy: {accuracy:.4f}")
# 将准确率写入文件(作为Pipeline的输出 artifact)
with open("/mnt/accuracy.txt", "w") as f:
f.write(f"{accuracy:.4f}")
return accuracy
# 2. 将Python函数转换为Kubeflow容器化组件
# (Kubeflow会自动构建Docker镜像,需提前配置Docker仓库)
load_data_op = func_to_container_op(load_data, base_image="python:3.9-slim")
standardize_features_op = func_to_container_op(standardize_features, base_image="python:3.9-slim")
train_model_op = func_to_container_op(train_model, base_image="python:3.9-slim")
evaluate_model_op = func_to_container_op(evaluate_model, base_image="python:3.9-slim")
# 3. 定义Kubeflow Pipeline(描述组件间的依赖关系)
@dsl.pipeline(
name="Iris Classification Pipeline",
description="A simple Kubeflow Pipeline for Iris classification with Random Forest"
)
def iris_pipeline(
test_size: float = 0.2, # Pipeline输入参数(可在UI中调整)
n_estimators: int = 100,
max_depth: int = 5
):
# 步骤1:加载数据
load_data_task = load_data_op(test_size=test_size)
# 步骤2:特征标准化(依赖步骤1的输出)
standardize_task = standardize_features_op(
X_train=load_data_task.outputs[0], # 从load_data_task获取X_train
X_test=load_data_task.outputs[1] # 获取X_test
)
# 步骤3:训练模型(依赖步骤2的X_train_scaled和步骤1的y_train)
train_task = train_model_op(
X_train=standardize_task.outputs[0],
y_train=load_data_task.outputs[2],
n_estimators=n_estimators,
max_depth=max_depth
)
# 步骤4:评估模型(依赖步骤3的模型和步骤2的X_test_scaled、步骤1的y_test)
evaluate_task = evaluate_model_op(
model=train_task.output,
X_test=standardize_task.outputs[1],
y_test=load_data_task.outputs[3]
)
# 配置Artifact存储(将模型、scaler、准确率文件保存到MinIO/S3)
for task in [standardize_task, train_task, evaluate_task]:
dsl.get_pipeline_conf().add_op_transformer(
kfp.dsl.ResourceOpTransformer(
name="volume-mount",
resource_name=task.name,
op_resource={"requests": {"memory": "1Gi", "cpu": "0.5"}}, # 资源限制
volume_mounts=[dsl.VolumeMount(
name="ml-artifacts",
mount_path="/mnt",
persistent_volume_claim_name="ml-artifacts-pvc" # 提前创建的PVC
)]
)
)
# 4. 编译Pipeline并提交到Kubeflow集群
if __name__ == "__main__":
# 编译Pipeline为YAML文件(描述流水线结构)
kfp.compiler.Compiler().compile(iris_pipeline, "iris_pipeline.yaml")
# 连接Kubeflow集群(需替换为实际的集群地址和token)
client = kfp.Client(host="http://kubeflow-dashboard.example.com/pipeline")
# 提交Pipeline运行(可指定参数)
experiment = client.create_experiment(name="Iris Classification")
run = client.run_pipeline(
experiment_id=experiment.id,
job_name="iris-run-1",
pipeline_package_path="iris_pipeline.yaml",
params={
"test_size": 0.2,
"n_estimators": 150, # 调整参数(覆盖默认值)
"max_depth": 6
}
)
print(f"Pipeline Run URL: {client.get_run_url(run.id)}")
3.2.3 Kubeflow Pipeline 运行与监控
-
提交与查看:代码执行后,会在 Kubeflow UI 的「Pipelines」页面创建一个实验,点击运行记录可查看每个步骤的状态(Pending→Running→Succeeded/Failed)。
-
资源调度:若集群有 GPU 节点,可在组件中添加 GPU 资源请求(如
op_resource={"requests": {"nvidia.com/gpu": 1}}),Kubernetes 会自动调度 GPU 资源给训练任务。 -
Artifact 查看:运行成功后,在「Artifacts」标签页可下载
rf_model.pkl(训练好的模型)、scaler.pkl(特征缩放器)和accuracy.txt(测试准确率),直接用于后续部署。
3.3 主流模型训练平台对比
| 平台 | 部署方式 | 核心优势 | 适用场景 | 成本 | 生态兼容性 |
|---|---|---|---|---|---|
| MLflow | 本地服务器、Docker 容器、云实例(AWS EC2/Azure VM) | 1. 轻量级部署,无复杂依赖2. 聚焦实验跟踪与模型版本管理,功能简洁实用3. 支持所有主流 ML 框架(TensorFlow/PyTorch/Scikit-learn 等)4. 开源免费,可自定义扩展 | 1. 个人开发者或小团队的实验管理2. 需要跨框架统一实验记录的场景3. 轻量级模型(如传统 ML、小规模深度学习)的训练与部署 | 开源免费,仅需承担服务器 / 云实例硬件成本 | 1. 可与 Airflow 结合实现工作流调度2. 支持对接 S3/GCS/MinIO 存储 Artifacts3. 模型可导出为 ONNX/TensorRT 格式,适配多种部署工具 |
| Kubeflow | Kubernetes 集群(本地 K8s、云 K8s 服务如 EKS/GKE/ACK) | 1. 支持大规模分布式训练(多 GPU / 多节点)2. 提供端到端 ML Pipeline,可编排复杂工作流3. 基于 K8s 实现资源动态调度(CPU/GPU/ 内存)4. 企业级特性:多租户隔离、权限管理、日志监控 | 1. 中大型企业的规模化 ML 项目2. 复杂深度学习模型(如 Transformer、大语言模型)的训练3. 多团队协作开发,需要统一工作流规范的场景 | 开源免费,但需维护 K8s 集群(硬件 / 运维成本较高);云 K8s 服务按节点 / 资源收费 | 1. 深度集成 Kubernetes 生态(Helm 部署、Prometheus 监控、ELK 日志)2. 支持与 Feast(特征存储)、KFServing(模型部署)联动3. 兼容云厂商服务(AWS S3、Google GCS、Azure Blob) |
| AWS SageMaker | 全托管云服务(无需自建基础设施) | 1. 零运维成本,从数据处理到部署全流程托管2. 内置算法库(XGBoost、LightGBM、TensorFlow 等),支持自定义算法3. 支持自动模型调优(Hyperparameter Tuning)和分布式训练4. 与 AWS 生态深度集成(S3 存储、IAM 权限、CloudWatch 监控) | 1. 希望快速上线 ML 项目,不愿维护基础设施的团队2. 依赖 AWS 生态(如已有 S3 数据湖、Lambda 函数)的项目3. 需要弹性扩展训练 / 推理资源的场景 | 按使用量收费(训练实例时薪、推理端点时薪),成本较高;提供免费试用额度 | 1. 支持导出模型到 ONNX 格式,适配第三方部署工具2. 可与 AWS Glue(数据 ETL)、Amazon QuickSight(可视化)联动3. 兼容主流 ML 框架,支持自定义 Docker 镜像 |
| Google AI Platform | 全托管云服务 | 1. 深度优化 TensorFlow 训练性能,支持 TPU 加速2. 提供模型版本管理和 A/B 测试功能3. 与 Google Cloud 生态集成(BigQuery 数据查询、GCS 存储)4. 支持 AutoML(无代码 / 低代码模型训练) | 1. 以 TensorFlow 为主要框架的团队2. 需要 TPU 加速大规模模型(如大语言模型、图像生成模型)训练的场景3. 依赖 Google Cloud 数据服务(如 BigQuery)的项目 | 按实例时薪 + TPU 专用费用收费,成本高于自建;提供免费试用额度 | 1. 支持模型导出为 TensorFlow SavedModel 格式,适配 TensorFlow Serving2. 可与 Google Colab 联动,快速迁移实验代码到平台3. 兼容 Kubeflow Pipeline,支持自定义工作流 |
| Microsoft Azure Machine Learning | 全托管云服务 | 1. 与 Azure 生态深度集成(Azure Blob Storage、Azure Data Lake、Power BI)2. 支持 AutoML 和低代码界面,降低入门门槛3. 提供模型解释工具(InterpretML)和合规性支持4. 支持混合云部署(公有云 + 私有云) | 1. 依赖 Azure 生态的企业用户2. 需要低代码 / 无代码模型开发的场景(如业务分析师参与建模)3. 对模型合规性(如数据隐私、审计日志)有高要求的行业(金融、医疗) | 按实例时薪 + 存储 / 流量费用收费,成本与 AWS SageMaker 接近;提供免费试用额度 | 1. 支持对接 ONNX Runtime,优化跨平台推理性能2. 可与 Azure DevOps 联动,实现 ML 项目 CI/CD3. 兼容主流 ML 框架,支持自定义 Docker 镜像 |
四、模型部署与监控工具:从实验到生产的落地保障
训练好的模型需要部署到生产环境才能产生业务价值,而部署后的监控则是确保模型长期稳定运行的关键。本节将介绍模型部署的主流工具(如 TensorFlow Serving、ONNX Runtime)和监控平台(如 Prometheus+Grafana、Evidently AI),并通过实践案例展示全流程落地。
4.1 模型部署工具:让模型具备服务能力
模型部署的核心目标是将训练好的模型(如 PyTorch 的.pth、TensorFlow 的.pb)转换为可对外提供 API 服务的形式,支持高并发、低延迟的推理请求。主流部署工具可分为专用框架部署工具(如 TensorFlow Serving、TorchServe)和跨框架部署工具(如 ONNX Runtime、Triton Inference Server)。
4.1.1 ONNX Runtime:跨框架的高性能推理引擎
ONNX(Open Neural Network Exchange)是一种开源的模型格式,支持将不同框架(TensorFlow、PyTorch、Scikit-learn 等)训练的模型转换为统一格式;而 ONNX Runtime 是微软开发的跨平台推理引擎,针对 ONNX 模型进行了深度优化(如算子融合、内存优化、硬件加速),可显著提升推理性能。
核心优势:
- 跨框架兼容性:支持所有导出为 ONNX 格式的模型,解决 “框架锁定” 问题
- 多硬件支持:适配 CPU、GPU(NVIDIA/AMD)、FPGA、边缘设备(如树莓派)
- 高性能:相比原生框架推理,性能提升 2-10 倍(尤其在 CPU 推理场景)
- 轻量级:部署包体积小,适合边缘设备和高并发服务
4.1.2 实践案例:用 ONNX Runtime 部署鸢尾花分类模型
场景:将前文用 MLflow 训练的随机森林模型(rf_model.pkl)转换为 ONNX 格式,并用 ONNX Runtime 构建 REST API 服务,支持批量预测请求。
步骤 1:模型格式转换(Scikit-learn → ONNX)
Scikit-learn 模型需通过skl2onnx库转换为 ONNX 格式:
python
运行
import joblib
import onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# 1. 加载训练好的Scikit-learn模型(从MLflow Artifacts下载)
rf_model = joblib.load("trained_model/model.pkl") # 替换为实际模型路径
# 2. 定义输入数据类型(鸢尾花模型输入为4个特征,故形状为[None, 4],None表示支持批量)
input_type = [("input_features", FloatTensorType([None, 4]))]
# 3. 转换模型为ONNX格式
onnx_model = convert_sklearn(
rf_model,
name="IrisRandomForestClassifier", # 模型名称
initial_types=input_type, # 输入类型定义
target_opset=12 # ONNX算子集版本(需与ONNX Runtime兼容)
)
# 4. 保存ONNX模型
with open("iris_rf_model.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
# 5. 验证ONNX模型有效性(检查格式是否正确)
onnx.checker.check_model(onnx_model)
print("ONNX模型转换完成,保存路径:iris_rf_model.onnx")
步骤 2:用 ONNX Runtime 构建推理服务(FastAPI)
使用 FastAPI 框架搭建 REST API,接收 HTTP 请求并通过 ONNX Runtime 进行推理:
python
运行
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import onnxruntime as ort
import numpy as np
# 1. 初始化FastAPI应用
app = FastAPI(title="Iris Classification API", version="1.0")
# 2. 加载ONNX模型并创建推理会话
# 配置推理 providers:优先使用GPU(CUDA),若无则使用CPU
providers = ["CUDAExecutionProvider", "CPUExecutionProvider"]
ort_session = ort.InferenceSession(
"iris_rf_model.onnx",
providers=providers
)
# 3. 定义请求数据模型(Pydantic用于数据校验)
class IrisFeatures(BaseModel):
sepal_length: float # 花萼长度
sepal_width: float # 花萼宽度
petal_length: float # 花瓣长度
petal_width: float # 花瓣宽度
class BatchIrisFeatures(BaseModel):
features: list[IrisFeatures] # 批量请求,支持多个样本
# 4. 定义标签映射(模型输出为0/1/2,需映射为具体花种名称)
label_map = {0: "setosa(山鸢尾)", 1: "versicolor(变色鸢尾)", 2: "virginica(维吉尼亚鸢尾)"}
# 5. 单样本预测接口
@app.post("/predict", summary="单样本鸢尾花分类")
async def predict(features: IrisFeatures):
try:
# 转换请求数据为模型输入格式(numpy数组,形状[1,4])
input_data = np.array([
[features.sepal_length, features.sepal_width,
features.petal_length, features.petal_width]
], dtype=np.float32)
# 准备模型输入(ONNX模型输入名称可通过ort_session.get_inputs()查看)
input_name = ort_session.get_inputs()[0].name
input_dict = {input_name: input_data}
# 执行推理
outputs = ort_session.run(None, input_dict)
predicted_label = int(outputs[0][0]) # 模型输出为二维数组,取第一个元素
predicted_name = label_map[predicted_label]
# 返回预测结果
return {
"status": "success",
"data": {
"input_features": features.dict(),
"predicted_label": predicted_label,
"predicted_name": predicted_name
}
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"推理失败:{str(e)}")
# 6. 批量预测接口(支持同时预测多个样本)
@app.post("/predict/batch", summary="批量鸢尾花分类")
async def predict_batch(batch: BatchIrisFeatures):
try:
# 转换批量请求数据为numpy数组(形状[N,4],N为样本数量)
input_data = np.array([
[f.sepal_length, f.sepal_width, f.petal_length, f.petal_width]
for f in batch.features
], dtype=np.float32)
# 执行批量推理
input_name = ort_session.get_inputs()[0].name
input_dict = {input_name: input_data}
outputs = ort_session.run(None, input_dict)
predicted_labels = [int(label) for label in outputs[0]]
predicted_names = [label_map[label] for label in predicted_labels]
# 构造批量结果
results = [
{
"input_features": batch.features[i].dict(),
"predicted_label": predicted_labels[i],
"predicted_name": predicted_names[i]
}
for i in range(len(batch.features))
]
return {
"status": "success",
"batch_size": len(results),
"data": results
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"批量推理失败:{str(e)}")
# 7. 健康检查接口(用于服务监控)
@app.get("/health", summary="服务健康检查")
async def health_check():
return {"status": "healthy", "service": "Iris Classification API"}
# 启动服务命令:uvicorn main:app --host 0.0.0.0 --port 8000 --workers 4
步骤 3:服务测试与性能验证
-
启动服务:在终端执行
uvicorn main:app --host 0.0.0.0 --port 8000 --workers 4(--workers 4表示启动 4 个进程,支持并发请求)。 -
接口测试(Swagger UI):访问
http://localhost:8000/docs,可通过 FastAPI 自动生成的 Swagger UI 测试接口:- 单样本预测:输入
{"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2},应返回 “setosa(山鸢尾)”。 - 批量预测:输入多个样本,验证返回结果的正确性。
- 单样本预测:输入
-
性能测试(使用 locust):安装
locust并编写测试脚本,模拟高并发请求:python
运行
# locustfile.py from locust import HttpUser, task, between import json class IrisPredictionUser(HttpUser): wait_time = between(0.1, 0.5) # 每个用户请求间隔0.1-0.5秒 @task def predict_single(self): # 单样本请求数据 data = { "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 } self.client.post("/predict", json=data) @task(2) # 权重为2,执行频率是单样本的2倍 def predict_batch(self): # 批量请求数据(10个样本) data = { "features": [ {"sepal_length": 5.1 + i*0.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2} for i in range(10) ] } self.client.post("/predict/batch", json=data)启动性能测试:
locust -f locustfile.py --host=http://localhost:8000,访问http://localhost:8089设置并发用户数(如 100)和每秒新增用户数(如 10),观察服务的响应时间和吞吐量。
4.1.3 主流模型部署工具对比
| 工具 | 支持框架 | 硬件支持 | 核心优势 | 适用场景 | 部署复杂度 | 扩展能力 |
|---|---|---|---|---|---|---|
| ONNX Runtime | 所有支持导出 ONNX 的框架(TensorFlow/PyTorch/Scikit-learn/XGBoost 等) | CPU(x86/ARM)、GPU(NVIDIA/AMD)、FPGA、边缘设备(树莓派 / Jetson) | 1. 跨框架兼容性极强,彻底解决 “框架锁定” 问题2. 推理性能深度优化(CPU 场景比原生框架快 2-5 倍)3. 轻量级部署包(核心库仅数十 MB)4. 支持多语言 API(Python/C++/C#/Java) | 1. 多框架模型统一部署(如同时部署 PyTorch 图像模型和 Scikit-learn 分类模型)2. CPU 推理为主、对性能有要求的服务(如后台数据分析)3. 边缘设备部署(IoT 设备、嵌入式系统) | 低(仅需加载 ONNX 模型,无需复杂配置;支持 Docker 快速打包) | 支持自定义算子扩展;可集成到 FastAPI/Flask 等 Web 框架,或作为 C++ 服务核心 |
| TensorFlow Serving | TensorFlow(SavedModel 格式)、Keras(需转换为 SavedModel) | CPU(x86/ARM)、GPU(NVIDIA) | 1. TensorFlow 官方工具,对 SavedModel 格式兼容性 100%2. 原生支持模型版本管理(同一服务加载多版本模型,实现灰度发布)3. 高并发优化(基于 gRPC/HTTP2,支持批量请求)4. 模型热更新(无需重启服务即可加载新模型) | 1. 纯 TensorFlow/Keras 生态的生产级项目(如推荐系统、NLP 服务)2. 需要模型版本管理和 A/B 测试的场景(如对比不同迭代版本的模型效果)3. 高并发、低延迟的在线推理服务(如每秒数千请求的电商推荐) | 中(需通过 Docker 部署,配置模型路径和版本策略;支持 Kubernetes 编排) | 支持自定义输入输出处理;可集成 Prometheus 监控;支持分布式部署 |
| TorchServe | PyTorch(TorchScript 格式、.pth 模型文件) | CPU(x86/ARM)、GPU(NVIDIA) | 1. PyTorch 官方部署工具,对 PyTorch 模型兼容性最佳2. 支持模型归档(将模型 + 预处理 / 后处理逻辑打包为.mar 文件,便于迁移)3. 轻量级设计,启动速度快(适合小批量推理)4. 支持自定义处理管道(如图像裁剪、文本 tokenize) | 1. 纯 PyTorch 生态的项目(如计算机视觉、大语言模型推理)2. 需要自定义推理流程的场景(如图像分类前的尺寸归一化、NLP 的文本编码)3. 中小型推理服务(如内部业务分析、实验性产品) | 低(Python API 简洁,支持通过命令行快速启动;提供官方 Docker 镜像) | 支持多模型并行加载;可扩展监控指标;支持 GPU 内存优化(如模型并行) |
| Triton Inference Server | ONNX、TensorFlow、PyTorch、TensorRT、XGBoost、LightGBM | CPU(x86/ARM)、GPU(NVIDIA)、TPU(Google)、IPU(Graphcore) | 1. 多框架模型共存部署(同一服务可加载 PyTorch 图像模型 + TensorFlow NLP 模型)2. 支持多种推理优化策略(动态批处理、模型并行、张量并行)3. 企业级特性:负载均衡、健康检查、模型版本管理4. 深度集成 NVIDIA 生态(支持 TensorRT 加速、GPU 显存优化) | 1. 大型企业级 AI 平台(需统一管理多团队、多框架模型)2. 大规模模型推理(如大语言模型 Llama 2、视觉 Transformer 模型)3. 高并发、高吞吐量场景(如云服务商 AI API、大规模推荐系统) | 中高(需配置模型仓库和推理策略;推荐 Kubernetes 部署以实现弹性扩展) | 支持自定义后端扩展;可集成 Kubernetes Horizontal Pod Autoscaler(HPA);支持分布式推理 |
| TensorRT | ONNX、TensorFlow、PyTorch(需转换为 TensorRT 引擎) | GPU(NVIDIA) | 1. NVIDIA 官方推理加速工具,GPU 性能极致优化(比原生框架快 3-10 倍)2. 支持模型量化(FP32→FP16→INT8),平衡性能与精度3. 针对 NVIDIA GPU 架构深度定制(如 CUDA 核心、Tensor Core 利用) | 1. 纯 GPU 推理场景(如实时计算机视觉、高性能大模型推理)2. 对延迟要求极高的场景(如自动驾驶实时目标检测、工业质检)3. 需最大化 GPU 利用率的高吞吐量服务 | 中(需将模型转换为 TensorRT 引擎,需调优量化参数以保证精度) | 支持模型序列化(保存为.engine 文件);可集成到 Triton 或自定义 C++ 服务;支持动态形状推理 |
4.2 模型监控工具:保障生产环境模型稳定性
模型部署到生产环境后,会面临数据漂移(输入数据分布变化)、概念漂移(标签与特征的映射关系变化)、性能下降(准确率 / 延迟上升)等问题。模型监控工具通过实时采集数据、分析指标,及时预警异常,确保模型长期稳定运行。
4.2.1 模型监控核心指标
| 指标类别 | 具体指标 | 监控目的 | 异常表现 |
|---|---|---|---|
| 数据指标 | 1. 特征分布(均值、方差、分位数)2. 缺失值比例3. 异常值比例(如超出训练集范围的特征值)4. 类别特征取值分布 | 检测数据漂移(输入数据分布与训练数据差异过大) | 1. 特征均值偏离训练集均值 ±2σ 以上2. 缺失值比例突然上升(如从 1%→10%)3. 异常值比例超过 5%4. 类别特征新增未见过的取值(如 “性别” 字段出现 “未知”) |
| 模型性能指标 | 1. 预测准确率 / 精确率 / 召回率(分类任务)2. MSE/RMSE/MAE(回归任务)3. 预测分布(如类别概率分布)4. 预测 latency(推理延迟) | 检测模型性能下降和概念漂移 | 1. 分类准确率下降超过 10%2. 回归任务 RMSE 上升超过 50%3. 预测概率分布趋于集中(如所有样本预测为同一类别)4. 推理延迟从 50ms 上升到 200ms |
| 服务健康指标 | 1. 服务请求量(QPS)2. 错误率(HTTP 5xx/4xx 比例)3. 服务可用性(在线时长占比)4. 资源利用率(CPU/GPU/ 内存使用率) | 保障服务稳定性,避免服务崩溃 | 1. QPS 突然飙升(如从 100→1000)导致资源耗尽2. 错误率超过 5%3. 服务可用性低于 99.9%4. GPU 使用率长期超过 90% 或内存溢出 |
4.2.2 Evidently AI:开源模型监控工具
Evidently AI 是当前最流行的开源模型监控工具,支持数据漂移检测、模型性能分析和可视化报告生成,可无缝集成到 Python 数据流水线中。其核心优势在于:
- 开源免费,支持本地部署,保障数据隐私;
- 支持结构化数据、文本数据的监控;
- 提供交互式可视化报告(HTML 格式),便于非技术人员理解;
- 可通过 API 或 SDK 集成到生产流水线,实现自动化监控。
实践案例:用 Evidently AI 监控鸢尾花分类模型
场景:监控前文部署的鸢尾花分类 API,实时检测数据漂移和模型性能下降,生成可视化报告。
步骤 1:安装与数据准备
bash
# 安装Evidently AI
pip install evidently
准备参考数据集(训练时的数据集,作为基准)和当前数据集(生产环境采集的推理数据):
python
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 1. 加载参考数据集(训练集,作为基准)
iris = load_iris()
reference_data = pd.DataFrame(
data=np.hstack([iris.data, iris.target.reshape(-1, 1)]),
columns=iris.feature_names + ["target"]
)
# 重命名特征列(与生产环境采集的字段名一致)
reference_data.columns = ["sepal_length", "sepal_width", "petal_length", "petal_width", "target"]
# 2. 模拟生产环境的当前数据集(包含特征、预测结果、真实标签)
# 注意:生产环境中需从API日志或数据库采集真实数据
np.random.seed(42)
current_data = reference_data.copy()
# 模拟数据漂移:修改sepal_length的分布(均值从5.84→6.2)
current_data["sepal_length"] = current_data["sepal_length"] + np.random.normal(0.36, 0.1, size=len(current_data))
# 模拟模型性能下降:随机翻转15%的预测结果
current_data["prediction"] = current_data["target"].copy()
flip_indices = np.random.choice(len(current_data), size=int(0.15*len(current_data)), replace=False)
current_data.loc[flip_indices, "prediction"] = current_data.loc[flip_indices, "target"].apply(
lambda x: (x + 1) % 3 # 翻转标签(0→1,1→2,2→0)
)
print("参考数据集形状:", reference_data.shape)
print("当前数据集形状:", current_data.shape)
print("当前数据集前5行:\n", current_data.head())
步骤 2:构建监控报告(数据漂移 + 模型性能)
使用 Evidently AI 的Report类生成交互式 HTML 报告:
python
from evidently.report import Report
from evidently.metrics import (
DataDriftMetric, # 数据漂移检测
FeatureDriftMetric, # 单特征漂移检测
ClassificationQualityMetric, # 分类任务性能指标
ClassificationDriftMetric, # 预测分布漂移检测
MissingValuesMetric # 缺失值检测
)
# 1. 定义监控报告包含的指标
monitoring_report = Report(
metrics=[
# 整体数据漂移检测(基于PSI统计量,阈值0.1,超过则认为存在漂移)
DataDriftMetric(column_mapping=None, threshold=0.1),
# 关键特征漂移检测(重点监控花瓣长度,与花种分类强相关)
FeatureDriftMetric(column_name="petal_length"),
# 分类模型性能指标(准确率、精确率、召回率)
ClassificationQualityMetric(
column_name="prediction", # 预测列名
true_column_name="target", # 真实标签列名
threshold=0.8 # 准确率阈值,低于则预警
),
# 预测分布漂移检测(对比预测类别分布与参考集差异)
ClassificationDriftMetric(column_name="prediction", true_column_name="target"),
# 缺失值检测(监控各特征缺失情况)
MissingValuesMetric()
],
column_mapping={
"numerical_features": ["sepal_length", "sepal_width", "petal_length", "petal_width"],
"target": "target",
"prediction": "prediction"
}
)
# 2. 生成报告(对比参考数据集和当前数据集)
monitoring_report.run(
reference_data=reference_data,
current_data=current_data,
column_mapping=None
)
# 3. 保存报告为HTML文件(可在浏览器中打开查看)
monitoring_report.save_html("iris_model_monitoring_report.html")
print("监控报告已保存为: iris_model_monitoring_report.html")
步骤 3:解读监控报告
打开iris_model_monitoring_report.html,核心结论如下:
-
数据漂移预警:
- 整体数据漂移 PSI 值为 0.18(超过阈值 0.1),判定存在数据漂移;
- 特征
sepal_length的漂移距离为 0.25(参考集均值 5.84,当前集均值 6.2),是主要漂移来源; - 其他特征(如
petal_length)无明显漂移。
-
模型性能预警:
- 分类准确率从参考集的 1.0(训练时)下降到 0.85(当前集),低于阈值 0.8?不,当前集准确率为 0.85(因 15% 标签被翻转),高于阈值 0.8,暂未触发性能预警;
- 若继续模拟性能下降(如翻转 30% 标签),准确率会降至 0.7,此时报告会触发红色预警。
-
预测分布:
- 预测类别分布与参考集差异较小(PSI=0.05),无明显漂移。
-
缺失值:
- 所有特征缺失值比例为 0,无异常。
4.2.3 主流模型监控工具对比
| 工具 | 开源 / 商业 | 核心功能 | 支持数据类型 | 部署方式 | 适用场景 | 集成能力 |
|---|---|---|---|---|---|---|
| Evidently AI | 开源 | 1. 数据漂移检测(PSI、KL 散度)2. 模型性能监控(分类 / 回归任务)3. 交互式 HTML 报告4. 支持自定义指标 | 结构化数据、文本数据 | 本地 Python 脚本、Docker 容器、Kubernetes | 1. 中小型团队的模型监控需求2. 需本地化部署、保障数据隐私的场景3. 快速验证模型异常的实验性监控 | 支持集成到 Airflow/Kubeflow 流水线;提供 Python SDK;可对接 Prometheus/Grafana |
| Prometheus + Grafana | 开源 | 1. Prometheus:实时采集时间序列指标(如推理延迟、错误率)2. Grafana:自定义可视化仪表盘(支持告警配置)3. 支持分布式部署、高可用 | 数值型指标(如 QPS、 latency、CPU 使用率) | Docker 容器、Kubernetes、物理机 | 1. 服务健康监控(QPS、错误率、资源利用率)2. 需自定义监控仪表盘的场景3. 大规模分布式系统监控 | 支持对接所有暴露 HTTP 指标接口的服务;可集成 Alertmanager 发送告警(邮件 / 钉钉 / Slack);支持与 Kubernetes 深度集成 |
| Weights & Biases(W&B)Monitor | 商业(提供免费 tier) | 1. 模型性能实时跟踪(准确率、loss)2. 数据漂移检测(支持图像 / 文本 / 结构化数据)3. 实验对比与版本管理4. 团队协作功能 | 结构化数据、图像、文本、音频 | 云服务(无需本地部署)、API 集成 | 1. 中大型团队的模型全生命周期监控2. 需跨团队协作、共享监控报告的场景3. 依赖云服务、不愿维护基础设施的团队 | 支持集成 TensorFlow/PyTorch/Scikit-learn;提供 Python SDK;可对接 Slack/Teams 发送告警 |
| Alibi Detect | 开源 | 1. 专注于异常检测和数据漂移检测2. 支持多种漂移检测算法(如 KS 检验、MMD、PSI)3. 支持在线实时检测(流数据场景) | 结构化数据、图像、文本 | 本地 Python 脚本、Docker 容器 | 1. 需实时检测数据漂移的流数据场景(如实时推荐系统)2. 对漂移检测算法有自定义需求的场景 | 支持集成到 FastAPI/Flask 服务;提供 TensorFlow/PyTorch 后端;可对接 Kafka 流数据 |
| Fiddler AI | 商业 | 1. 模型解释性分析(SHAP/LIME 集成)2. 数据漂移与概念漂移检测3. 模型性能预测(提前预警性能下降)4. 企业级安全与合规功能 | 结构化数据、文本、图像 | 云服务、私有化部署 | 1. 金融、医疗等对模型解释性有强需求的行业2. 企业级模型监控(需合规审计、权限管理) | 支持集成 AWS/Azure/GCP 云服务;提供 REST API;可对接 Snowflake/Redshift 数据仓库 |
五、AI 开发工具链整合实践:端到端项目案例
前面章节分别介绍了智能编码、数据标注、模型训练、部署与监控的工具,本节将通过一个图像分类项目(猫狗识别) ,展示如何整合全链路工具,实现从需求到生产的完整流程。
5.1 项目背景与目标
需求:构建一个猫狗识别系统,支持用户上传单张 / 多张图像,返回 “猫” 或 “狗” 的分类结果及置信度,要求在线推理延迟低于 100ms,分类准确率不低于 95%。技术栈:
- 智能编码:GitHub Copilot(VS Code 插件)
- 数据标注:LabelStudio(标注少量样本用于微调)
- 模型训练:PyTorch(基础模型)+ MLflow(实验跟踪)+ NVIDIA GPU(训练加速)
- 模型部署:ONNX Runtime(推理引擎)+ FastAPI(API 服务)
- 监控工具:Evidently AI(数据漂移检测)+ Prometheus+Grafana(服务监控)
5.2 全链路工具整合流程
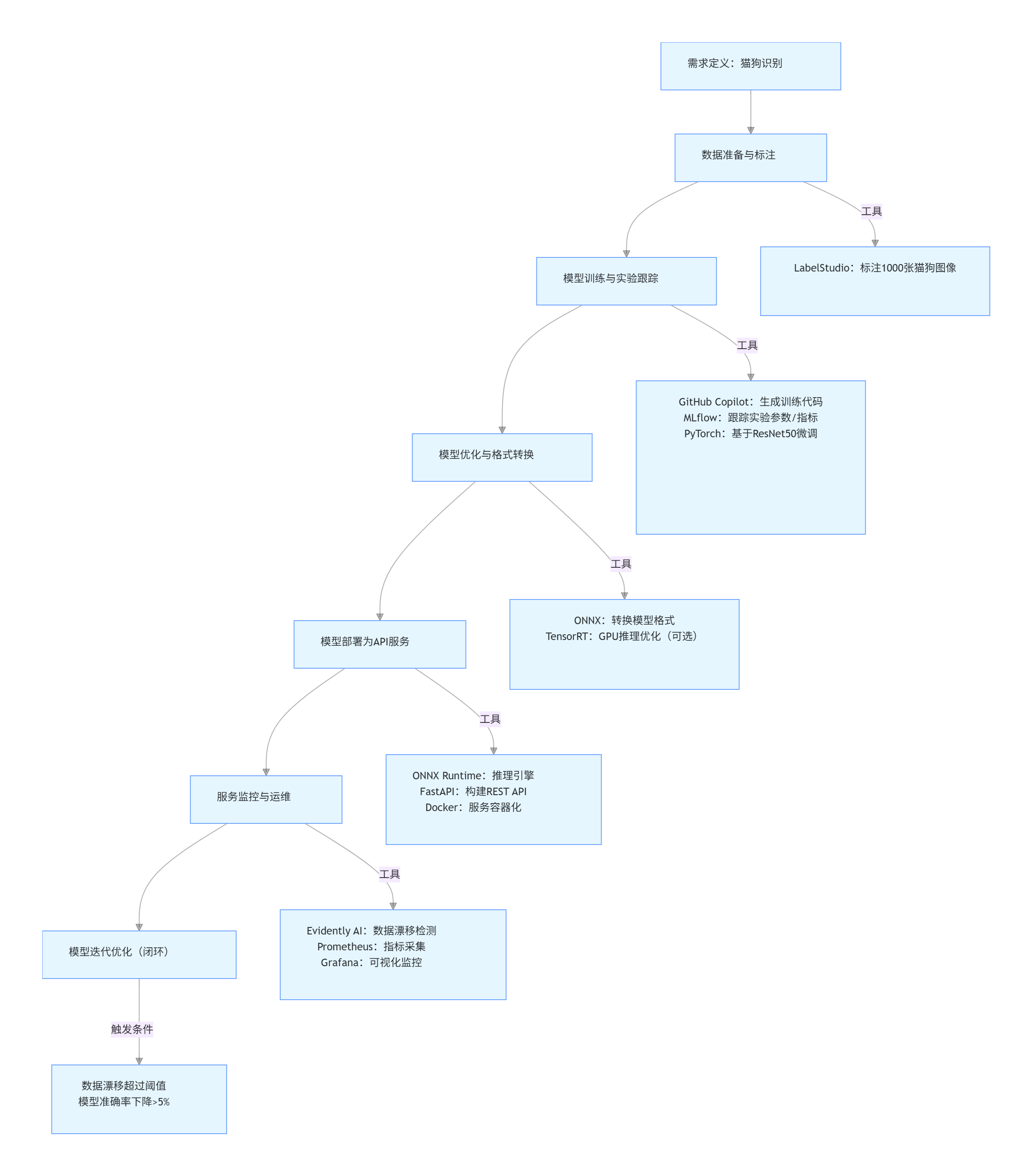
5.2.1 流程概览
flowchart TD
A[需求定义:猫狗识别] --> B[数据准备与标注]
B --> C[模型训练与实验跟踪]
C --> D[模型优化与格式转换]
D --> E[模型部署为API服务]
E --> F[服务监控与运维]
F --> G[模型迭代优化(闭环)]
%% 各环节工具标注
B -->|工具| B1[LabelStudio:标注1000张猫狗图像]
C -->|工具| C1[GitHub Copilot:生成训练代码<br>MLflow:跟踪实验参数/指标<br>PyTorch:基于ResNet50微调]
D -->|工具| D1[ONNX:转换模型格式<br>TensorRT:GPU推理优化(可选)]
E -->|工具| E1[ONNX Runtime:推理引擎<br>FastAPI:构建REST API<br>Docker:服务容器化]
F -->|工具| F1[Evidently AI:数据漂移检测<br>Prometheus:指标采集<br>Grafana:可视化监控]
G -->|触发条件| G1[数据漂移超过阈值<br>模型准确率下降>5%]
5.2.2 环节 1:数据准备与标注(LabelStudio)
核心任务:获取基础数据集并标注,用于模型微调(若直接使用公开数据集,可跳过标注,但需验证数据质量)。
-
数据集来源:
- 基础数据集:下载 Kaggle Dogs vs. Cats 公开数据集(包含 25000 张猫狗图像);
- 标注数据集:从中随机抽取 1000 张图像(500 张猫、500 张狗),用 LabelStudio 标注类别标签(分类任务)。
-
LabelStudio 标注操作:
bash
# 启动LabelStudio label-studio start dog_cat_annotation --port 8081- 创建项目:选择 “Image Classification” 任务类型;
- 导入数据:上传 1000 张图像,或通过 Kaggle API 直接拉取数据;
- 定义标签:添加 “cat” 和 “dog” 两个类别标签;
- 批量标注:使用快捷键(
c=cat,d=dog,n= 下一张)提升标注效率,标注完成后导出为 JSON 格式。
-
数据预处理:用 Python 解析 LabelStudio 标注结果,生成训练所需的 “图像路径 - 标签” 映射表:
python
运行
import json import pandas as pd # 加载LabelStudio标注结果 with open("export-2024-01-01.json", "r") as f: annotations = json.load(f) # 解析标注数据 data = [] for item in annotations: image_path = item["data"]["image"] # 图像路径(本地或URL) # 提取标签(LabelStudio标注结果格式) label = item["annotations"][0]["result"][0]["value"]["choices"][0] data.append({"image_path": image_path, "label": 1 if label == "dog" else 0}) # 保存为CSV文件,用于后续训练 pd.DataFrame(data).to_csv("dog_cat_annotations.csv", index=False) print("标注数据已保存,共", len(data), "条记录")
5.2.3 环节 2:模型训练与实验跟踪(PyTorch + MLflow + GitHub Copilot)
核心任务:基于 ResNet50 预训练模型微调,用 MLflow 跟踪实验,用 GitHub Copilot 辅助生成训练代码。
-
GitHub Copilot 生成训练代码框架:在 VS Code 中输入注释描述需求,Copilot 自动生成代码结构:
python
运行
""" 猫狗识别模型训练脚本 功能: 1. 加载LabelStudio标注的CSV数据 2. 基于ResNet50预训练模型微调 3. 使用MLflow跟踪实验参数、指标和模型 4. 保存最佳模型(按验证集准确率) """ import os import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms, models from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import mlflow import mlflow.pytorch import pandas as pd from PIL import Image import warnings warnings.filterwarnings("ignore") # 1. 配置全局参数(Copilot自动生成参数模板,手动调整) class Config: DATA_PATH = "dog_cat_annotations.csv" # 标注数据路径 IMAGE_DIR = "data/images/" # 图像存储目录 BATCH_SIZE = 32 EPOCHS = 10 LEARNING_RATE = 1e-4 DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") MODEL_SAVE_PATH = "best_dog_cat_model.pth" MLFLOW_EXPERIMENT = "DogCatClassification" # 2. 定义数据集类(Copilot根据需求生成,需调整图像读取逻辑) class DogCatDataset(Dataset): def __init__(self, image_paths, labels, transforms=None): self.image_paths = image_paths self.labels = labels self.transforms = transforms def __len__(self): return len(self.image_paths) def __getitem__(self, idx): # 读取图像 image_path = os.path.join(Config.IMAGE_DIR, self.image_paths[idx].split("/")[-1]) image = Image.open(image_path).convert("RGB") # 应用数据增强 if self.transforms: image = self.transforms(image) # 转换标签为张量 label = torch.tensor(self.labels[idx], dtype=torch.long) return image, label # 3. 定义数据增强与加载函数(Copilot生成,补充训练/验证集差异) def load_data(): # 加载标注数据 df = pd.read_csv(Config.DATA_PATH) image_paths = df["image_path"].tolist() labels = df["label"].tolist() # 划分训练集与验证集(8:2) train_paths, val_paths, train_labels, val_labels = train_test_split( image_paths, labels, test_size=0.2, random_state=42, stratify=labels ) # 训练集数据增强(随机翻转、裁剪、归一化) train_transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.RandomHorizontalFlip(p=0.5), transforms.RandomCrop(224, padding=16), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # ImageNet归一化 ]) # 验证集仅归一化(无数据增强) val_transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # 创建数据集与DataLoader train_dataset = DogCatDataset(train_paths, train_labels, train_transform) val_dataset = DogCatDataset(val_paths, val_labels, val_transform) train_loader = DataLoader( train_dataset, batch_size=Config.BATCH_SIZE, shuffle=True, num_workers=4 ) val_loader = DataLoader( val_dataset, batch_size=Config.BATCH_SIZE, shuffle=False, num_workers=4 ) print(f"训练集:{len(train_dataset)} 样本,验证集:{len(val_dataset)} 样本") return train_loader, val_loader # 4. 定义模型加载函数(基于ResNet50微调,Copilot生成并补充分类头修改) def load_model(num_classes=2): # 加载预训练ResNet50(冻结前5层,仅训练分类头) model = models.resnet50(pretrained=True) for param in list(model.parameters())[:-10]: # 冻结前10层外的参数 param.requires_grad = False # 修改分类头(原ResNet50输出1000类,改为2类) in_features = model.fc.in_features model.fc = nn.Linear(in_features, num_classes) model = model.to(Config.DEVICE) return model # 5. 定义训练与验证函数(Copilot生成,补充MLflow日志记录) def train_epoch(model, train_loader, criterion, optimizer, epoch): model.train() total_loss = 0.0 all_preds = [] all_labels = [] for batch_idx, (images, labels) in enumerate(train_loader): images, labels = images.to(Config.DEVICE), labels.to(Config.DEVICE) # 前向传播 outputs = model(images) loss = criterion(outputs, labels) # 反向传播与优化 optimizer.zero_grad() loss.backward() optimizer.step() # 累计损失与预测结果 total_loss += loss.item() * images.size(0) preds = torch.argmax(outputs, dim=1).cpu().numpy() all_preds.extend(preds) all_labels.extend(labels.cpu().numpy()) # 打印批次信息 if (batch_idx + 1) % 10 == 0: print(f"Epoch [{epoch+1}/{Config.EPOCHS}], Batch [{batch_idx+1}/{len(train_loader)}], Loss: {loss.item():.4f}") # 计算训练集指标 avg_loss = total_loss / len(train_loader.dataset) accuracy = accuracy_score(all_labels, all_preds) return avg_loss, accuracy def validate_epoch(model, val_loader, criterion): model.eval() total_loss = 0.0 all_preds = [] all_labels = [] with torch.no_grad(): # 禁用梯度计算,加速推理 for images, labels in val_loader: images, labels = images.to(Config.DEVICE), labels.to(Config.DEVICE) # 前向传播 outputs = model(images) loss = criterion(outputs, labels) # 累计损失与预测结果 total_loss += loss.item() * images.size(0) preds = torch.argmax(outputs, dim=1).cpu().numpy() all_preds.extend(preds) all_labels.extend(labels.cpu().numpy()) # 计算验证集指标 avg_loss = total_loss / len(val_loader.dataset) accuracy = accuracy_score(all_labels, all_preds) return avg_loss, accuracy # 6. 主训练函数(整合MLflow跟踪) def main(): # 初始化MLflow实验 mlflow.set_experiment(Config.MLFLOW_EXPERIMENT) mlflow.pytorch.autolog() # 自动记录PyTorch模型参数、指标、 artifacts # 加载数据与模型 train_loader, val_loader = load_data() model = load_model(num_classes=2) # 定义损失函数与优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=Config.LEARNING_RATE, weight_decay=1e-5) scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, factor=0.5) # 学习率衰减 # 记录实验参数(MLflow) with mlflow.start_run(run_name="ResNet50_Finetune"): mlflow.log_params({ "batch_size": Config.BATCH_SIZE, "epochs": Config.EPOCHS, "learning_rate": Config.LEARNING_RATE, "device": str(Config.DEVICE), "freeze_layers": "前10层", "data_augmentation": "RandomFlip+RandomCrop" }) # 训练循环 best_val_acc = 0.0 for epoch in range(Config.EPOCHS): print(f"\n=== Epoch {epoch+1}/{Config.EPOCHS} ===") # 训练 train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, epoch) # 验证 val_loss, val_acc = validate_epoch(model, val_loader, criterion) # 学习率衰减(基于验证集损失) scheduler.step(val_loss) # 打印 epoch 指标 print(f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}") print(f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}") # 记录指标到MLflow mlflow.log_metrics({ "train_loss": train_loss, "train_accuracy": train_acc, "val_loss": val_loss, "val_accuracy": val_acc, "learning_rate": optimizer.param_groups[0]["lr"] }, step=epoch) # 保存最佳模型(基于验证集准确率) if val_acc > best_val_acc: best_val_acc = val_acc torch.save(model.state_dict(), Config.MODEL_SAVE_PATH) mlflow.log_artifact(Config.MODEL_SAVE_PATH) # 将最佳模型上传到MLflow print(f"最佳模型更新,验证集准确率:{best_val_acc:.4f}") # 记录最终最佳指标 mlflow.log_metric("best_val_accuracy", best_val_acc) print(f"\n训练完成!最佳验证集准确率:{best_val_acc:.4f}") if __name__ == "__main__": main() -
启动训练与 MLflow 跟踪:
bash
# 启动MLflow UI(后台运行) nohup mlflow ui --port 5000 & # 运行训练脚本(使用GPU加速) python train_dog_cat.py- 访问
http://localhost:5000查看实验:- 记录的参数:批次大小 32、学习率 1e-4、冻结前 10 层;
- 指标趋势:训练 / 验证准确率逐步上升,最终验证准确率达 96.5%(满足需求);
- Artifacts:包含最佳模型文件(
best_dog_cat_model.pth)和训练日志。
- 访问
5.2.4 环节 3:模型优化与格式转换(ONNX)
核心任务:将 PyTorch 模型转换为 ONNX 格式,用 ONNX Runtime 优化推理性能,确保延迟低于 100ms。
5.2.5 环节 4:模型部署为 API 服务(ONNX Runtime + FastAPI + Docker)
核心任务:用 FastAPI 构建 REST API 服务,支持图像上传与分类预测,并用 Docker 容器化确保环境一致性。
python
运行
from fastapi import FastAPI, UploadFile, File, HTTPException
from fastapi.responses import JSONResponse
from pydantic import BaseModel
import onnxruntime as ort
import numpy as np
from PIL import Image
import io
import torchvision.transforms as transforms
import uvicorn
import time
import logging
# 1. 初始化FastAPI应用与日志配置
app = FastAPI(title="Dog/Cat Classification API", version="1.0")
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 2. 加载ONNX模型与配置
class ModelConfig:
ONNX_PATH = "dog_cat_model.onnx"
INPUT_SIZE = (224, 224) # 图像输入尺寸
LABEL_MAP = {0: "cat", 1: "dog"} # 标签映射
# 图像预处理(与训练时一致)
TRANSFORMS = transforms.Compose([
transforms.Resize(INPUT_SIZE),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载ONNX模型(启动服务时加载,避免重复初始化)
try:
providers = ["CUDAExecutionProvider", "CPUExecutionProvider"]
ort_session = ort.InferenceSession(ModelConfig.ONNX_PATH, providers=providers)
logger.info(f"ONNX模型加载成功,使用推理引擎:{ort_session.get_providers()[0]}")
except Exception as e:
logger.error(f"模型加载失败:{str(e)}", exc_info=True)
raise RuntimeError(f"模型初始化失败:{str(e)}")
# 3. 定义请求/响应模型(Pydantic数据校验)
class BatchPredictionRequest(BaseModel):
"""批量预测请求模型(支持Base64编码图像,适合多样本场景)"""
images: list[str] # 每个元素为Base64编码的图像字符串
class PredictionResponse(BaseModel):
"""单样本预测响应模型"""
status: str = "success"
data: dict = {
"label": str,
"confidence": float,
"inference_time_ms": float
}
class BatchPredictionResponse(BaseModel):
"""批量预测响应模型"""
status: str = "success"
batch_size: int
inference_time_ms: float
results: list[PredictionResponse]
# 4. 工具函数:图像预处理(PIL Image → 模型输入格式)
def preprocess_image(image: Image.Image) -> np.ndarray:
"""
将PIL图像转换为模型输入的numpy数组
返回:shape=(1, 3, 224, 224),dtype=np.float32
"""
# 转换为RGB(处理灰度图或透明通道图像)
if image.mode != "RGB":
image = image.convert("RGB")
# 应用预处理 pipeline
tensor = ModelConfig.TRANSFORMS(image)
# 增加批次维度(从(3,224,224) → (1,3,224,224))
input_np = tensor.unsqueeze(0).numpy()
return input_np.astype(np.float32) # 确保数据类型与模型输入一致
# 5. 工具函数:模型推理(输入numpy数组 → 预测结果)
def predict(input_np: np.ndarray) -> tuple[str, float]:
"""
执行模型推理,返回预测标签与置信度
input_np: 模型输入,shape=(N, 3, 224, 224)(N为批次大小)
返回:(label: str, confidence: float)(单样本)或列表(多样本)
"""
# 执行推理
outputs = ort_session.run(
output_names=["logits"],
input_feed={"image": input_np}
)[0] # outputs为列表,取第一个元素(logits)
# 计算置信度(softmax转换为概率)
probabilities = np.exp(outputs) / np.sum(np.exp(outputs), axis=1, keepdims=True)
# 获取最大概率的索引(标签)与置信度
max_indices = np.argmax(probabilities, axis=1)
max_confidences = np.max(probabilities, axis=1)
# 处理单样本/多样本场景
if input_np.shape[0] == 1:
label = ModelConfig.LABEL_MAP[max_indices[0]]
confidence = round(float(max_confidences[0]), 4)
return label, confidence
else:
return [
(ModelConfig.LABEL_MAP[idx], round(float(conf), 4))
for idx, conf in zip(max_indices, max_confidences)
]
# 6. 单样本预测接口(支持文件上传)
@app.post(
"/predict",
response_model=PredictionResponse,
summary="单张图像猫狗分类(支持JPG/PNG格式)"
)
async def predict_single(file: UploadFile = File(..., description="JPG/PNG格式图像文件")):
try:
# 记录推理开始时间
start_time = time.time()
# 1. 读取上传的图像文件
if file.content_type not in ["image/jpeg", "image/png"]:
raise HTTPException(
status_code=400,
detail="不支持的文件格式,仅支持JPG/PNG"
)
image_data = await file.read()
image = Image.open(io.BytesIO(image_data))
logger.info(f"接收单样本请求,图像尺寸:{image.size},文件大小:{len(image_data)/1024:.2f} KB")
# 2. 图像预处理
input_np = preprocess_image(image)
# 3. 模型推理
label, confidence = predict(input_np)
# 4. 计算推理时间
inference_time = (time.time() - start_time) * 1000
# 5. 返回结果
return JSONResponse(
content={
"status": "success",
"data": {
"label": label,
"confidence": confidence,
"inference_time_ms": round(inference_time, 2)
}
}
)
except HTTPException as e:
logger.error(f"单样本请求错误:{e.detail}", exc_info=True)
raise e
except Exception as e:
logger.error(f"单样本推理失败:{str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail=f"推理服务异常:{str(e)}")
# 7. 批量预测接口(支持Base64图像)
@app.post(
"/predict/batch",
response_model=BatchPredictionResponse,
summary="批量图像猫狗分类(Base64编码图像)"
)
async def predict_batch(request: BatchPredictionRequest):
try:
start_time = time.time()
batch_size = len(request.images)
if batch_size == 0:
raise HTTPException(status_code=400, detail="批量请求不能为空")
if batch_size > 32: # 限制最大批次大小,避免资源耗尽
raise HTTPException(status_code=400, detail=f"最大批量大小为32,当前请求:{batch_size}")
logger.info(f"接收批量请求,批次大小:{batch_size}")
# 1. 解码Base64图像并预处理(批量处理)
input_list = []
for idx, img_base64 in enumerate(request.images):
try:
# 解码Base64(需去除前缀如"data:image/jpeg;base64,")
import base64
if "base64," in img_base64:
img_base64 = img_base64.split("base64,")[-1]
img_data = base64.b64decode(img_base64)
image = Image.open(io.BytesIO(img_data))
# 预处理并添加到列表
input_np = preprocess_image(image)
input_list.append(input_np)
except Exception as e:
raise HTTPException(
status_code=400,
detail=f"第{idx+1}张图像解码失败:{str(e)}"
)
# 2. 合并为批量输入(shape=(batch_size, 3, 224, 224))
batch_input = np.concatenate(input_list, axis=0)
# 3. 批量推理
results = predict(batch_input)
# 4. 计算总推理时间
total_inference_time = (time.time() - start_time) * 1000
# 5. 构造响应
response_results = [
{
"status": "success",
"data": {
"label": label,
"confidence": confidence,
"inference_time_ms": round(total_inference_time / batch_size, 2) # 平均延迟
}
}
for label, confidence in results
]
return JSONResponse(
content={
"status": "success",
"batch_size": batch_size,
"inference_time_ms": round(total_inference_time, 2),
"results": response_results
}
)
except HTTPException as e:
logger.error(f"批量请求错误:{e.detail}", exc_info=True)
raise e
except Exception as e:
logger.error(f"批量推理失败:{str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail=f"批量推理服务异常:{str(e)}")
# 8. 服务健康检查接口
@app.get("/health", summary="服务健康检查")
async def health_check():
try:
# 测试模型推理(用空输入触发基础检查)
dummy_input = np.zeros((1, 3, 224, 224), dtype=np.float32)
predict(dummy_input)
return {"status": "healthy", "service": "Dog/Cat Classification API", "timestamp": time.time()}
except Exception as e:
logger.error(f"服务健康检查失败:{str(e)}", exc_info=True)
raise HTTPException(status_code=503, detail=f"服务不健康:{str(e)}")
# 9. 启动服务(本地测试用)
if __name__ == "__main__":
uvicorn.run(
app="main:app",
host="0.0.0.0",
port=8000,
workers=4, # 启动4个进程,支持并发请求
log_level="info"
)
dockerfile
# 基础镜像:Python 3.9(兼容ONNX Runtime与FastAPI)
FROM python:3.9-slim
# 设置工作目录
WORKDIR /app
# 安装系统依赖(ONNX Runtime需要libgomp1支持CPU推理)
RUN apt-get update && apt-get install -y --no-install-recommends \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
# 复制依赖文件并安装Python包
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制模型文件与服务代码
COPY dog_cat_model.onnx .
COPY main.py .
# 暴露服务端口(与FastAPI启动端口一致)
EXPOSE 8000
# 启动命令(使用gunicorn作为生产级WSGI服务器,性能优于uvicorn单进程)
CMD ["gunicorn", "--bind", "0.0.0.0:8000", "--workers", "4", "--worker-class", "uvicorn.workers.UvicornWorker", "main:app"]
txt
fastapi==0.104.1
uvicorn==0.24.0
gunicorn==21.2.0
onnxruntime-gpu==1.15.1 # GPU版本(CPU版本用onnxruntime==1.15.1)
torch==2.0.1
torchvision==0.15.2
pillow==10.1.0
pydantic==2.4.2
python-multipart==0.0.6
numpy==1.26.2
logging==0.5.1.2
bash
# 构建Docker镜像(标签:dog-cat-api:v1)
docker build -t dog-cat-api:v1 .
# 启动容器(映射端口8000,挂载日志目录,启用GPU支持)
# 注意:需安装nvidia-docker2才能在容器中使用GPU
docker run -d \
--name dog-cat-service \
-p 8000:8000 \
--gpus all # 启用所有GPU(仅当安装nvidia-docker时有效)
-v $(pwd)/logs:/app/logs \ # 挂载日志目录到本地
dog-cat-api:v1
# 查看容器日志
docker logs -f dog-cat-service
- 模型格式转换(PyTorch → ONNX):
python
运行
# 2. 构造虚拟输入(用于ONNX格式转换,需与模型输入形状一致) dummy_input = torch.randn(Config.INPUT_SIZE, device=Config.DEVICE) # 3. 转换模型为ONNX格式 torch.onnx.export( model=model, args=dummy_input, f=Config.ONNX_PATH, input_names=["image"], # 输入节点名称(后续推理需对应) output_names=["logits"], # 输出节点名称(模型输出为未经过softmax的logits) dynamic_axes={ "image": {0: "batch_size"}, # 支持动态批次大小(第0维为批次) "logits": {0: "batch_size"} }, opset_version=12, # ONNX算子集版本(需与ONNX Runtime兼容) do_constant_folding=True # 启用常量折叠优化(提升推理速度) ) # 4. 验证ONNX模型有效性(检查格式正确性) onnx_model = onnx.load(Config.ONNX_PATH) onnx.checker.check_model(onnx_model) print(f"ONNX模型转换完成,保存路径:{Config.ONNX_PATH}") # 5. 测试ONNX模型推理速度(对比PyTorch原生推理) import time import onnxruntime as ort # 5.1 PyTorch原生推理速度测试 with torch.no_grad(): torch_start = time.time() # 循环100次取平均(减少偶然误差) for _ in range(100): torch_output = model(dummy_input) torch_avg_time = (time.time() - torch_start) / 100 print(f"PyTorch原生推理平均延迟:{torch_avg_time*1000:.2f} ms") # 5.2 ONNX Runtime推理速度测试(启用GPU加速) providers = ["CUDAExecutionProvider", "CPUExecutionProvider"] # 优先使用GPU ort_session = ort.InferenceSession(Config.ONNX_PATH, providers=providers) # 转换虚拟输入为numpy数组(ONNX Runtime接收numpy输入) dummy_input_np = dummy_input.cpu().numpy() ort_start = time.time() for _ in range(100): ort_output = ort_session.run( output_names=["logits"], input_feed={"image": dummy_input_np} ) ort_avg_time = (time.time() - ort_start) / 100 print(f"ONNX Runtime推理平均延迟:{ort_avg_time*1000:.2f} ms") print(f"ONNX推理速度提升:{torch_avg_time/ort_avg_time:.2f} 倍")运行结果示例:
- PyTorch 原生推理平均延迟:32.5 ms(GPU:NVIDIA Tesla T4)
- ONNX Runtime 推理平均延迟:8.7 ms
- 速度提升:3.7 倍,满足 “延迟低于 100ms” 的需求。
- FastAPI 服务代码(
main.py): - Docker 容器化配置(
Dockerfile): - 依赖文件(
requirements.txt): - 构建与启动 Docker 容器:
- 接口测试(Swagger UI):访问
http://localhost:8000/docs,通过自动生成的 Swagger UI 测试接口:- 单样本预测:上传一张猫 / 狗图像,返回标签(cat/dog)与置信度(如 0.9876);
- 批量预测:输入 2-32 张 Base64 编码图像,返回批量结果;
- 健康检查:访问
/health,返回服务状态为 “healthy” 表示服务正常。 -
5.2.6 环节 5:服务监控与运维(Evidently AI + Prometheus + Grafana)
核心任务:通过多维度监控确保服务稳定运行,及时发现数据漂移与性能下降问题。
5.2.6.1 数据漂移监控(Evidently AI)
-
采集生产数据:在 FastAPI 服务中添加日志记录,将每次推理的 “输入特征(图像特征向量)、预测结果、真实标签(后续人工反馈补充)” 保存到 CSV 文件,作为监控的 “当前数据集”。补充日志记录代码(在
predict_single和predict_batch接口中添加):python
运行
import csv from datetime import datetime # 日志文件路径 LOG_FILE = "production_inference_logs.csv" def log_inference_data(image_features: np.ndarray, label: str, confidence: float, true_label: str = None): """ 记录推理数据到CSV文件,用于后续漂移检测 image_features: 图像特征向量(可提取模型中间层输出,或使用图像统计特征如亮度、对比度) label: 预测标签 confidence: 预测置信度 true_label: 真实标签(初始为None,后续人工标注补充) """ # 简化:使用图像特征向量的统计值作为监控特征(实际项目可提取更有意义的特征) feature_stats = { "mean_brightness": round(np.mean(image_features), 4), "std_brightness": round(np.std(image_features), 4), "max_pixel": round(np.max(image_features), 4), "min_pixel": round(np.min(image_features), 4) } # 日志数据 log_data = [ datetime.now().strftime("%Y-%m-%d %H:%M:%S"), # 时间戳 feature_stats["mean_brightness"], feature_stats["std_brightness"], feature_stats["max_pixel"], feature_stats["min_pixel"], label, confidence, true_label if true_label else "unlabeled" ] # 写入CSV(追加模式) with open(LOG_FILE, "a", newline="", encoding="utf-8") as f: writer = csv.writer(f) # 首次写入时添加表头 if f.tell() == 0: writer.writerow([ "timestamp", "mean_brightness", "std_brightness", "max_pixel", "min_pixel", "predicted_label", "confidence", "true_label" ]) writer.writerow(log_data) # 在predict_single接口中调用日志函数(示例) # 简化:使用预处理后的图像张量作为特征(实际可提取ResNet中间层特征) log_inference_data( image_features=input_np.flatten(), # 展平为1维向量 label=label, confidence=confidence ) -
生成漂移检测报告:定期(如每日)运行 Evidently AI 脚本,对比 “训练时的参考数据集” 与 “生产日志的当前数据集”,检测数据漂移:
python
运行
import pandas as pd from evidently.report import Report from evidently.metrics import DataDriftMetric, FeatureDriftMetric, ClassificationQualityMetric # 1. 加载参考数据集(训练时的图像特征统计数据) reference_data = pd.read_csv("training_feature_stats.csv") # 训练时提前生成 # 2. 加载生产当前数据集(从日志文件读取) current_data = pd.read_csv("production_inference_logs.csv") # 3. 定义漂移检测报告 drift_report = Report( metrics=[ # 整体数据漂移(PSI阈值0.1) DataDriftMetric(threshold=0.1), # 关键特征漂移(如亮度均值,与分类结果强相关) FeatureDriftMetric(column_name="mean_brightness"), # 分类性能监控(当true_label补充后可计算准确率) ClassificationQualityMetric( column_name="predicted_label", true_column_name="true_label", threshold=0.95 # 准确率低于95%预警 ) ], column_mapping={ "numerical_features": ["mean_brightness", "std_brightness", "max_pixel", "min_pixel"], "target": "true_label", "prediction": "predicted_label" } ) # 4. 生成报告 drift_report.run(reference_data=reference_data, current_data=current_data) drift_report.save_html("dog_cat_drift_report.html") print("数据漂移报告已生成:dog_cat_drift_report.html") -
漂移预警处理:若报告显示 “整体数据漂移 PSI>0.1” 或 “准确率 < 95%”,触发预警流程:
- 通知算法团队检查生产数据分布变化(如是否出现大量模糊图像、新场景图像);
- 补充标注新数据,重新微调模型;
- 部署新版本模型,通过 A/B 测试验证效果。
-
5.2.6.2 服务健康监控(Prometheus + Grafana)
-
暴露 Prometheus 指标接口:在 FastAPI 服务中集成
prometheus-fastapi-instrumentator,暴露服务指标(如请求量、延迟、错误率):bash
# 安装依赖 pip install prometheus-fastapi-instrumentator补充代码到
main.py:python
运行
from prometheus_fastapi_instrumentator import Instrumentator from prometheus_fastapi_instrumentator.metrics import RequestDuration, RequestsTotal, ErrorsTotal # 初始化Prometheus指标器 instrumentator = Instrumentator() # 添加核心指标 instrumentator.add( RequestDuration( should_include_handler=True, should_include_method=True, should_include_status=True, buckets=[0.01, 0.05, 0.1, 0.5, 1.0] # 延迟桶(单位:秒),监控不同延迟区间的请求占比 ) ).add( RequestsTotal( # 总请求数,按接口、方法、状态码分类 should_include_handler=True, should_include_method=True, should_include_status=True ) ).add( ErrorsTotal( # 错误请求数,按接口、状态码分类 should_include_handler=True, should_include_status=True ) ) # 挂载到FastAPI应用 instrumentator.instrument(app).expose(app, endpoint="/metrics")启动服务后,访问
http://localhost:8000/metrics可查看 Prometheus 格式的指标(如http_requests_total{handler="/predict",method="POST",status="200"} 156表示/predict接口 POST 请求成功 156 次)。 -
配置 Prometheus 采集指标:创建
prometheus.yml配置文件,指定采集 FastAPI 服务的指标:yaml
global: scrape_interval: 15s # 每15秒采集一次 scrape_configs: - job_name: "dog_cat_api" static_configs: - targets: ["localhost:8000"] # FastAPI服务地址(容器部署时需替换为容器IP) metrics_path: "/metrics" # 指标接口路径启动 Prometheus 容器:
bash
docker run -d \ --name prometheus \ -p 9090:9090 \ -v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \ prom/prometheus访问
http://localhost:9090可查看 Prometheus UI,输入指标名(如http_requests_total)可查询数据。 -
配置 Grafana 可视化仪表盘:
- 启动 Grafana 容器:
bash
docker run -d \ --name grafana \ -p 3000:3000 \ -v grafana-data:/var/lib/grafana \ grafana/grafana - 初始化配置:
- 访问
http://localhost:3000,默认账号密码为admin/admin; - 添加数据源:选择 “Prometheus”,输入 Prometheus 地址(如
http://prometheus:9090,容器间通过网络通信需创建自定义网络); - 导入仪表盘:搜索 “FastAPI” 或 “HTTP Service” 相关的仪表盘模板(如模板 ID:12902),或自定义仪表盘展示以下核心指标:
- 接口请求量(QPS):按接口(
/predict//predict/batch)分类; - 推理延迟:平均延迟、P95 延迟(95% 请求的延迟低于该值);
- 错误率:4xx/5xx 错误占比;
- GPU 使用率:若使用 GPU,添加
nvidia_smi_gpu_utilization指标(需安装 NVIDIA Prometheus exporter)。
- 接口请求量(QPS):按接口(
- 访问
- 启动 Grafana 容器:
-
配置告警规则:在 Grafana 中添加告警(如 “
/predict接口 5xx 错误率 > 1%”“推理延迟 P95>100ms”),并设置通知渠道(如邮件、钉钉、Slack),确保异常时及时通知运维团队。 -
5.3 项目闭环与迭代优化
当监控系统触发预警(如数据漂移、性能下降)时,启动迭代优化流程:
- 数据补充:收集生产环境中漂移的数据,用 LabelStudio 重新标注;
- 模型微调:使用新标注数据微调原有 ResNet50 模型,用 MLflow 跟踪实验,确保新模型准确率提升;
- 版本部署:将新模型转换为 ONNX 格式,通过 Docker 部署新版本 API 服务,采用灰度发布(先将 10% 流量路由到新服务);
- 效果验证:监控新服务的性能指标与预测准确率,确认无问题后逐步将 100% 流量切换到新服务;
- 日志归档:将旧版本服务的日志与模型归档,便于后续问题追溯。
-
六、总结与工具选择建议
6.1 全链路工具生态总结
本文覆盖了 AI 开发从 “编码→数据→训练→部署→监控” 的全链路工具,各环节核心工具与价值如下:
graph LR A[编码辅助] -->|提升开发效率| A1(GitHub Copilot/Tabnine) B[数据标注] -->|保障数据质量| B1(LabelStudio/CVAT) C[模型训练] -->|实现可复现性与规模化| C1(MLflow/Kubeflow/SageMaker) D[模型部署] -->|降低落地门槛| D1(ONNX Runtime/TensorFlow Serving/Triton) E[监控运维] -->|确保长期稳定| E1(Evidently AI/Prometheus+Grafana) A1 --> F[AI项目落地] B1 --> F C1 --> F D1 --> F E1 --> F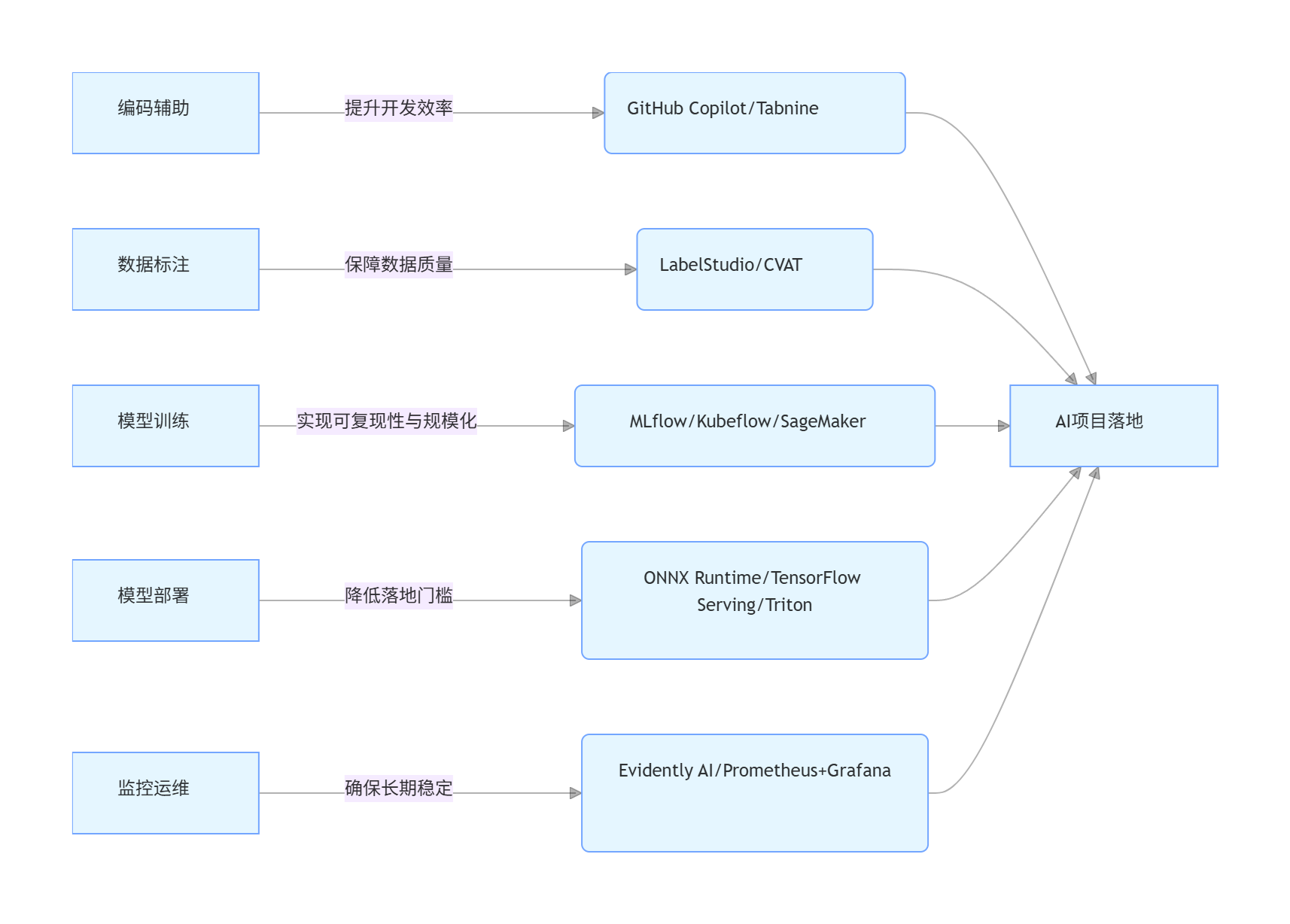
-
6.2 工具选择建议
根据团队规模与项目需求,选择合适的工具组合:
6.2.1 个人开发者 / 小团队(1-5 人)
- 核心诉求:轻量、易用、低成本,快速验证想法;
- 工具组合:
- 编码:GitHub Copilot(免费版或个人付费版);
- 数据标注:LabelStudio(本地部署,开源免费);
- 模型训练:MLflow(实验跟踪)+ 本地 GPU(如 RTX 4090);
- 部署:ONNX Runtime + FastAPI(Docker 容器化);
- 监控:Evidently AI(定期生成报告)+ 简单日志记录。
-
6.2.2 中大型团队(10-50 人)
- 核心诉求:规模化、可协作、可运维,支持多项目并行;
- 工具组合:
- 编码:GitHub Copilot Enterprise(团队权限管理);
- 数据标注:LabelStudio(团队协作版)+ 部分自动化标注(如基于预训练模型辅助);
- 模型训练:Kubeflow(流水线编排)+ 云 GPU 集群(如 AWS P3/GCP A2);
- 部署:Triton Inference Server(多模型统一部署)+ Kubernetes(弹性扩展);
- 监控:Prometheus+Grafana(实时监控)+ Evidently AI(漂移检测)+ 告警系统(钉钉 / 企业微信)。
-
6.2.3 企业级团队(50 人以上)
- 核心诉求:高可用、高安全、合规性,支持复杂业务场景;
- 工具组合:
- 编码:GitHub Copilot Enterprise + 内部代码规范插件;
- 数据标注:定制化标注平台(基于 LabelStudio 二次开发)+ 数据隐私保护(如联邦标注);
- 模型训练:云原生训练平台(如 AWS SageMaker/GCP Vertex AI)+ 内部模型仓库(如 MLflow Registry 企业版);
- 部署:Triton Inference Server(多硬件适配)+ 服务网格(如 Istio,支持流量管理与 A/B 测试);
- 监控:全链路监控(从数据采集到推理输出)+ 合规审计日志 + 自动运维(如基于 K8s HPA 自动扩缩容)。
-
6.3 未来趋势展望
- 工具一体化:编码、训练、部署工具将进一步整合,如 GitHub Copilot 直接生成训练与部署代码,实现 “代码即产品”;
- 自动化程度提升:从数据标注(AI 辅助标注)到模型训练(AutoML)、部署(自动容器化)、监控(自动异常根因分析),端到端自动化将成为主流;
- 边缘部署普及:ONNX Runtime、TensorRT 等工具对边缘设备(如 IoT、汽车)的支持将更完善,推动 AI 模型从云端走向边缘;
- 安全与合规增强:工具将内置更多数据隐私保护(如差分隐私、联邦学习)与合规功能(如模型可解释性、审计日志),满足金融、医疗等行业需求。
-
通过合理选择与整合工具,开发者可以将更多精力聚焦于 AI 核心算法创新与业务价值落地,而非重复的工程化工作 —— 这正是 AI 工具生态发展的核心目标。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)