
机器学习之样本不均衡
在机器学习中,数据不平衡问题是最为常见、最头疼的问题,如何解决数据不平衡问题直接影响模型效果,在此总结一下数据不平衡的解决方案,喜欢的朋友请点赞、收藏、关注。1.1 样本不均衡现象样本(类别)样本不平衡(class-imbalance)指的是分类任务中不同类别的训练样例数目差别很大的情况,一般地,样本类别比例(Imbalance Ratio)(多数类vs少数类)明显大于1:1(如4:1)就可以归为
在机器学习中,数据不平衡问题是最为常见、最头疼的问题,如何解决数据不平衡问题直接影响模型效果,在此总结一下数据不平衡的解决方案,喜欢的朋友请点赞、收藏、关注。
1.1 样本不均衡现象
样本(类别)样本不平衡(class-imbalance)指的是分类任务中不同类别的训练样例数目差别很大的情况,一般地,样本类别比例(Imbalance Ratio)(多数类vs少数类)明显大于1:1(如4:1)就可以归为样本不均衡的问题。现实中,样本不平衡是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,智能监控安全检测,而且对于有些任务而言少数样本更为重要。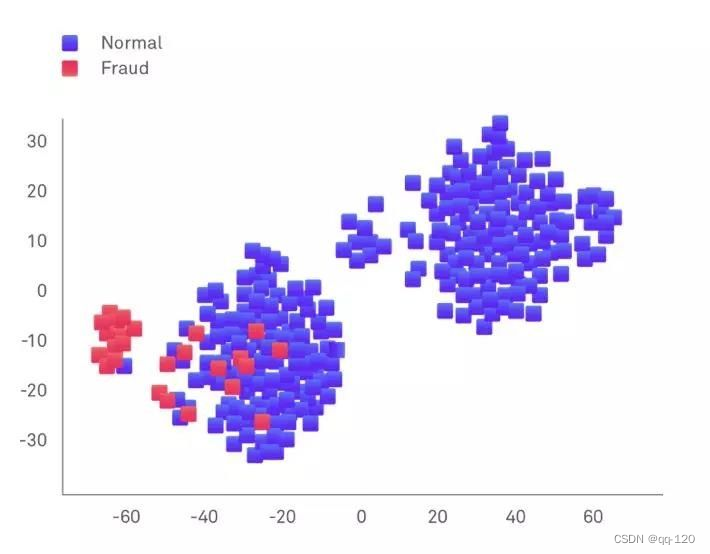
1.2 不均衡的根本影响
很多时候我们遇到样本不均衡问题时,很直接的反应就是去“打破”这种不平衡。但是样本不均衡有什么影响?有必要去解决吗?
具体举个例子,在一个欺诈识别的案例中,好坏样本的占比是1000:1,而如果我们直接拿这个比例去学习模型的话,因为扔进去模型学习的样本大部分都是好的,就很容易学出一个把所有样本都预测为好的模型,而且这样预测的概率准确率还是非常高的。而模型最终学习的并不是如何分辨好坏,而是学习到了”好远比坏的多“这样的先验信息,凭着这个信息把所有样本都判定为“好”就可以了。这样就背离了模型学习去分辨好坏的初衷了。
所以,样本不均衡带来的根本影响是:模型会学习到训练集中样本比例的这种先验性信息,以致于实际预测时就会对多数类别有侧重(可能导致多数类精度更好,而少数类比较差)。如下图,类别不均衡情况下的分类边界会偏向“侵占”少数类的区域。更重要的一点,这会影响模型学习更本质的特征,影响模型的鲁棒性。
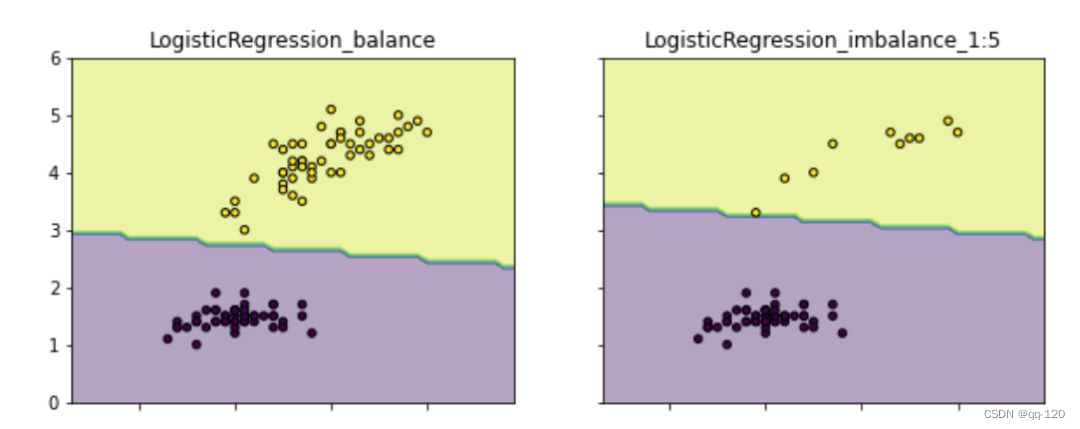
总结一下也就是,我们通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。
1.3 判断解决不均衡的必要性
从分类效果出发,通过上面的例子可知,不均衡对于分类结果的影响不一定是不好的,那什么时候需要解决样本不均衡?
判断任务是否复杂:复杂度学习任务的复杂度与样本不平衡的敏感度是成正比的(参见《Survey on deep learning with class imbalance》),对于简单线性可分任务,样本是否均衡影响不大。需要注意的是,学习任务的复杂度是相对意义上的,得从特征强弱、数据噪音情况以及模型容量等方面综合评估。
判断训练样本的分布与真实样本分布是否一致且稳定,如果分布是一致的,带着这种正确点的先验对预测结果影响不大。但是,还需要考虑到,如果后面真实样本分布变了,这个样本比例的先验就有副作用了。
判断是否出现某一类别样本数目非常稀少的情况,这时模型很有可能学习不好,类别不均衡是需要解决的,如选择一些数据增强的方法,或者尝试如异常检测的单分类模型。
二、样本不均衡解决方法
基本上,在学习任务有些难度的前提下,不均衡解决方法可以归结为:通过某种方法使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的。以消除模型对不同类别的偏向性,学习到更为本质的特征。本文从数据样本、模型算法、目标(损失)函数、评估指标等方面,对个中的解决方法进行探讨。
2.1 样本层面
2.1.1欠采样、过采样
最直接的处理方式就是样本数量的调整了,常用的可以:
欠采样:减少多数类的数量(如随机欠采样、NearMiss、ENN)。
过采样:尽量多地增加少数类的的样本数量(如随机过采样、以及2.1.2数据增强方法),以达到类别间数目均衡。
还可结合两者做混合采样(如Smote+ENN)。
具体还可以参见【scikit-learn的http://imbalanced-learn.org/stable/user_guide.html以及github的awesome-imbalanced-learning】
2.1.2 数据增强
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多数据的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值,从而提高模型的学习效果。如下列举常用的方法:
基于样本变换的数据增强
样本变换数据增强即采用预设的数据变换规则进行已有数据的扩增,包含单样本数据增强和多样本数据增强。
单样本增强(主要用于图像):主要有几何操作、颜色变换、随机擦除、添加噪声等方法产生新的样本,可参见imgaug开源库。
参考链接:一文解决样本不均衡

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)