
ssd目标检测训练自己的数据_目标检测工具箱mmdetection,训练自己的数据
1:训练之前需要改动的地方针对coco数据集的: 1、定义数据种类,需要修改的地方在mmdetection/mmdet/datasets/coco.py。把CLASSES的那个tuple改为自己数据集对应的种类tuple即可。例如: CLASSES = ('speedboat', 'boat', 'Clamp', 'Drainage_Plate')2、接着在mmdetection/mmdet/co

1:训练之前需要改动的地方针对coco数据集的:
1、定义数据种类,需要修改的地方在mmdetection/mmdet/datasets/coco.py。把CLASSES的那个tuple改为自己数据集对应的种类tuple即可。例如: CLASSES = ('speedboat', 'boat', 'Clamp', 'Drainage_Plate')
2、接着在mmdetection/mmdet/core/evaluation/class_names.py修改coco_classes数据集类别,这个关系到后面test的时候结果图中显示的类别名称。 def coco_classes(): return [ 'Glass_Insulator', 'Composite_Insulator', 'Clamp', 'Drainage_Plate' ] 3、修改configs/faster_rcnn_r50_fpn_1x.py中的model字典中的num_classes、data字典中的img_scale和optimizer中的lr(学习率)。例如:
num_classes=5,#类别数+1
img_scale=(640,478), #输入图像尺寸的最大边与最小边(train、val、test这三处都要修改)
optimizer = dict(type='SGD', lr=0.0025, momentum=0.9, weight_decay=0.0001) #当gpu数量为8时,lr=0.02;当gpu数量为4时,lr=0.01;我只要一个gpu,所以设置lr=0.00254、在mmdetection的目录下新建work_dirs文件夹
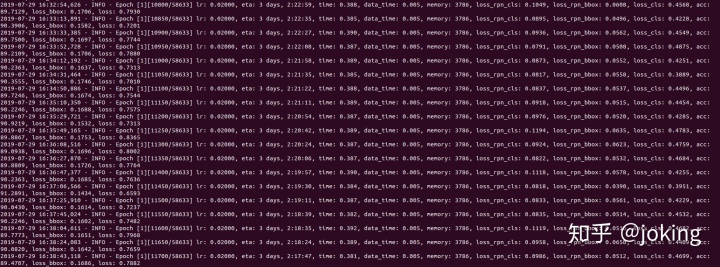
训练的指令:
python tools/train.py configs/faster_rcnn_r50_fpn_1x.py --gpus 1 --validate --work_dir work_dirs
"""
2: 训练之前需要改动的地方针对VOC数据集的:
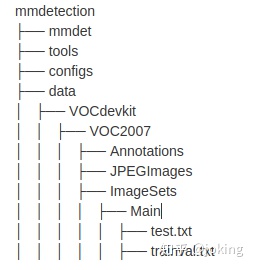
首先根据规范的VOC数据集导入到项目目录下,如下图所示:
1.然后复制configs/retinanet_x101_64x4d_fpn1x.py ,更名为my_data.py
2.修改其中my.py/dataset settings部分:
dataset_type = 'VOCDataset'
data_root = 'data/VOCdevkit/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
data = dict(
imgs_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset', # to avoid reloading datasets frequently
times=3,
dataset=dict(
type=dataset_type,
ann_file=[
data_root + 'VOC2007/ImageSets/Main/train.txt',#train.txt
],
img_prefix=[data_root + 'VOC2007/'],
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0.5,
with_mask=False,
with_crowd=False,
with_label=True)),
val=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/trainval.txt',
img_prefix=data_root + 'VOC2007/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=False,
with_label=True),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=False,
with_label=False,
test_mode=True))
3.修改mmdetection/mmdet/datasets/voc.py下classes为自己的类
class VOCDataset(XMLDataset):
CLASSES = ('fishingboat', 'boat', 'unmannedboat', 'float', 'islandreef', 'speedboat')
4、接着在mmdetection/mmdet/core/evaluation/class_names.py修改coco_classes数据集类别,这个关系到后面test的时候结果图中显示的类别名称。 def coco_classes(): return [ 'Glass_Insulator', 'Composite_Insulator', 'Clamp', 'Drainage_Plate' ]
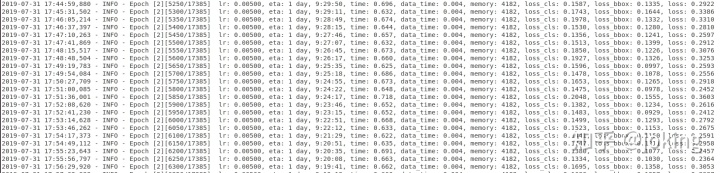
5::结果显示
"""
单GPU训练: python tools/train.py configs/my_data.py
多GPU训练: ./tools/dist_train.sh configs/my_data.py 2
########################
计算voc的map需要运行两步
1:python tools/test.py configs/my_data.py work_dirs/epoch_2.pth --out results.pkl --eval bbox --show
2:python tools/voc_eval.py results.pkl ./configs/my_data.py
###############################################################################################################################
可能存在的问题
1:::找不到batch_size?
The default learning rate in config files is for 8 GPUs and 2 img/gpu (batch size = 8*2 = 16).you need to set the learning rate proportional to the batch size if you use different GPUs or images per GPU, e.g., lr=0.01 for 4 GPUs * 2 img/gpu and lr=0.08 for 16 GPUs * 4 img/gpu.
2:::若是出现这个GPU内存问题,
要不就是输入图像的尺度太大,可以改成img_scale=(640,478),原配置文件img_scale=(1333, 800)
也有可能是lr=0.0001学习率太大.可以调小.原来的文件是lr = 0.01
3:::训练自己的VOC数据集 label=self.cat2label 报错
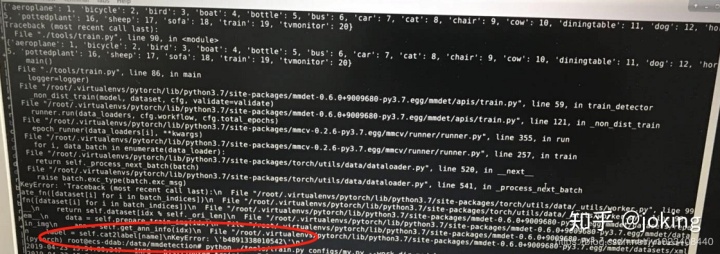
看了GitHub上的大佬的回答,报错的原因是self.cat2label值不对,所以根据大佬的建议,我print了self.cat2label值,发现果然不对,类还是VOC数据集的类,而不是我自己的类,我的类是‘b4891338010542’.我确定mmdetection/mmdet/datasets/voc.py下classes已修改无误,但任然打印的类是VOC数据集的类。
解决方案:
看到报错的文件路径了没,没错,就是这,这里还有个voc.py,进去将这里的classes也修改了就好了。
上面的路径是虚拟环境中mmdet的voc.py

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)