
optuna在深度学习上自动调参
文章目录1.背景2.安装3.在tensorflow上使用directionsampler4.实例4.1 定义模型、训练过程Trainertrain_stepval_steptrain4.2 objective函数定义params4.3 启动optunastorge5.图形化显示1.背景最近在烦恼怎么对深度学习进行调参,发现在optuna上可以实现。optuna可以和主流的机器学习框架进行融合,然后
·
文章目录
1.背景
最近在烦恼怎么对深度学习进行调参,发现在optuna上可以实现。
optuna可以和主流的机器学习框架进行融合,然后进行调参。同时调参后,还有查看结果对比的功能。
2.安装
直接使用pip进行安装:
pip install optuna
3.在tensorflow上使用
首先看一下官方案例:
import tensorflow as tf
import optuna
# 1. Define an objective function to be maximized.
def objective(trial):
# 2. Suggest values of the hyperparameters using a trial object.
n_layers = trial.suggest_int('n_layers', 1, 3)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten())
for i in range(n_layers):
num_hidden = trial.suggest_int(f'n_units_l{i}', 4, 128, log=True)
model.add(tf.keras.layers.Dense(num_hidden, activation='relu'))
model.add(tf.keras.layers.Dense(CLASSES))
...
return accuracy
# 3. Create a study object and optimize the objective function.
study = optuna.create_study(direction='maximize', sampler=optuna.samplers.TPESampler())
study.optimize(objective, n_trials=100)
案例上分为三步:
-
1)定义objective:这个函数主要使定义“模型构建”,“模型训练”,“参数更新”等;同时需要拿到一个值,这里是
accuracy,也就是保证准确率最大化maximize。 -
2)传入参数hyperparameters :用来控制哪些参数需要进行遍历,来找到最优的参数。
-
3)定义study:
direction
控制是以最大化还是最小化为准
sampler
指示您希望 Optuna 实施的采样器方法。
4.实例
4.1 定义模型、训练过程
class Trainer(object):
def __init__(self,
transformer_encoder,
discriminator_class,
optimizer,
epochs,
train_dataset_white,
val_dataset_white
) -> None:
super(Trainer, self).__init__()
self.train_dataset_white = train_dataset_white
self.val_dataset_white = val_dataset_white
self.epochs = epochs
self.transformer_encoder = transformer_encoder
self.discriminator_class = discriminator_class
self.optimizer = optimizer
train_step_signature = [
tf.TensorSpec(shape=(None, duel_seq_nums, seq_len), dtype=tf.float32),
tf.TensorSpec(shape=(None, sta_len), dtype=tf.float32),
tf.TensorSpec(shape=(None, 1), dtype=tf.int32),
]
@tf.function(input_signature=train_step_signature)
def train_step(self, inp_seq, inp_sta, label):
with tf.GradientTape() as tape:
enc_output = self.transformer_encoder(inp_seq, training = True)
predictions = self.discriminator_class(enc_output, inp_sta)
loss = loss_function(label, predictions)
trainable_variables = self.transformer_encoder.trainable_variables + self.discriminator_class.trainable_variables
gradients = tape.gradient(loss, trainable_variables)
self.optimizer.apply_gradients(zip(gradients, trainable_variables))
train_loss_class(loss)
predictions_label = tf.where(predictions >= 0.5, 1, 0)
train_precision_class(label, predictions_label)
train_recall_class(label, predictions_label)
return predictions
@tf.function(input_signature=train_step_signature)
def val_step(self, inp_seq, inp_sta, label):
enc_output = self.transformer_encoder(inp_seq, training = False)
predictions = self.discriminator_class(enc_output, inp_sta)
loss = loss_function(label, predictions)
val_loss_class(loss)
predictions_label = tf.where(predictions >= 0.5, 1, 0)
val_precision_class(label, predictions_label)
val_recall_class(label, predictions_label)
return predictions
def train(self):
# checkpoint and tensorboard
ckpt = tf.train.Checkpoint(transformer_encoder=self.transformer_encoder, discriminator_class=self.discriminator_class, optimizer=self.optimizer)
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
_checkpoint_path = checkpoint_path + "_" + current_time
# ckpt_manager = tf.train.CheckpointManager(ckpt, _checkpoint_path, max_to_keep=5)
train_summary_writer, val_summary_writer = tensorboard()
# # 如果检查点存在,则恢复最新的检查点。
# if ckpt_manager.latest_checkpoint:
# ckpt.restore(ckpt_manager.latest_checkpoint)
# logging.info('Latest checkpoint restored!!')
discriminator_step = 0
max_val_f1 = 0
discriminator_step = 0
for epoch in range(10):
start_epoch = time.time()
train_loss_class.reset_states()
train_precision_class.reset_states()
train_recall_class.reset_states()
val_loss_class.reset_states()
val_precision_class.reset_states()
val_recall_class.reset_states()
# Train
for start_index, parsed_dataset in enumerate(train_dataset_white):
seq, sta, l = rd.read_dataset(parsed_dataset)
predictions = self.train_step(seq, sta, l)
discriminator_step += 1
f1_score = (2 * train_precision_class.result() * train_recall_class.result()) / (train_precision_class.result() + train_recall_class.result())
with train_summary_writer.as_default():
# tf.summary.scalar('Generator loss', train_loss_gen_seq.result(), step=epoch)
tf.summary.scalar('Class loss', train_loss_class.result(), step=discriminator_step)
tf.summary.scalar('precision', train_precision_class.result(), step=discriminator_step)
tf.summary.scalar('recall', train_recall_class.result(), step=discriminator_step)
tf.summary.scalar('F1', f1_score, step=discriminator_step)
if start_index % 1000 == 0:
logging.info('Epoch {:2d} | Index {:5d} | Class Loss {:.4f} | Secs {:.4f}'.format(epoch, start_index, train_loss_class.result(), time.time() - start_epoch))
if start_index == 2000:
break
logging.info('Epoch {:2d} | Train Loss {:.4f} | Precision {:.4f} Recall {:.4f} F1 {:.4f}'.format(epoch, train_loss_class.result(),
train_precision_class.result(),
train_recall_class.result(),
f1_score))
# Val
val_predicted_all = np.zeros([0, 1])
val_label = np.zeros([0, 1])
for start_index, parsed_dataset in enumerate(val_dataset_white):
seq, sta, l = rd.read_dataset(parsed_dataset)
predictions = self.val_step(seq, sta, l)
val_predicted_all = np.concatenate([val_predicted_all, np.reshape(predictions.numpy(), [-1, 1])], axis=0)
val_label = np.concatenate([val_label, np.reshape(l.numpy(), [-1, 1])], axis=0)
pre, rec, val_f1, _ = precision_recall_fscore_support(val_label, np.where(val_predicted_all >= 0.5, 1, 0))
val_f1 = val_f1[1]
with val_summary_writer.as_default():
tf.summary.scalar('Class loss', val_loss_class.result(), step=epoch)
tf.summary.scalar('precision', val_precision_class.result(), step=epoch)
tf.summary.scalar('recall', val_recall_class.result(), step=epoch)
tf.summary.scalar('F1', val_f1, step=epoch)
logging.info('Epoch {:2d} | Val Loss {:.4f} | Precision {:.4f} Recall {:.4f} F1 {:.4f}'.format(epoch, val_loss_class.result(),
val_precision_class.result(),
val_recall_class.result(),
val_f1))
if max_val_f1 <= val_f1:
max_val_f1 = val_f1
# ckpt_save_path = ckpt_manager.save()
# logging.info('Saving checkpoint for epoch {} at {}'.format(epoch+1, ckpt_save_path))
logging.info("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
logging.info("Finish Epoch in %f \n" % (time.time() - start_epoch))
return max_val_f1
Trainer
- transformer_encoder、discriminator_class:模型
- optimizer:优化器
- train_dataset_white、val_dataset_white:训练集和验证集
train_step
训练过程
val_step
验证过程
train
启动模型训练
4.2 objective函数定义
def build_model(params):
# model
transformer_encoder = TransformerEncoder(
num_layers=params["num_layers"],
d_model=params["d_model"],
num_heads=hp.num_heads,
dff=params["dff"],
input_vocab_size=20,
target_vocab_size=22,
pe_input=100,
pe_target=100,
target_feature_len=21,
rate=params["dropout_rate"])
discriminator_class = DecoderClass()
optimizer = tf.keras.optimizers.Adam(params["learning_rate"])
logging.info('Model bulid: %f' % (time.time() - start_time))
trainer = Trainer(
transformer_encoder=transformer_encoder,
discriminator_class=discriminator_class,
optimizer=optimizer,
epochs=EPOCHS,
train_dataset_white=train_dataset_white,
val_dataset_white=val_dataset_white,
)
return trainer
def objective(trial):
params = {
'learning_rate': trial.suggest_float('learning_rate', 1e-4, 1e-3),
'num_layers': trial.suggest_categorical('num_layers', [1, 2, 3, 4]),
'd_model': trial.suggest_categorical('d_model', [64, 128, 256, 512]),
'dff': trial.suggest_int('dff', 128, 1024),
'dropout_rate': trial.suggest_categorical('dropout_rate', [0.0, 0.1, 0.2])
}
trainer = build_model(params)
max_val_f1 = trainer.train()
return max_val_f1
params
传入需要控制的参数
4.3 启动optuna
study = optuna.create_study(direction="maximize", sampler=optuna.samplers.TPESampler(), storage='sqlite:///db.sqlite3')
study.optimize(objective, n_trials=50)
storge
其中可以保存模型调参的结果
5.图形化显示
从上面保存文件db.sqlite3,然后再安装:optuna-dashboard
pip install optuna-dashboard
接着启动命令:
optuna-dashboard sqlite:///db.sqlite3
然后在浏览器输入:127.0.0.1:8080,就可以看到具体的图像结果: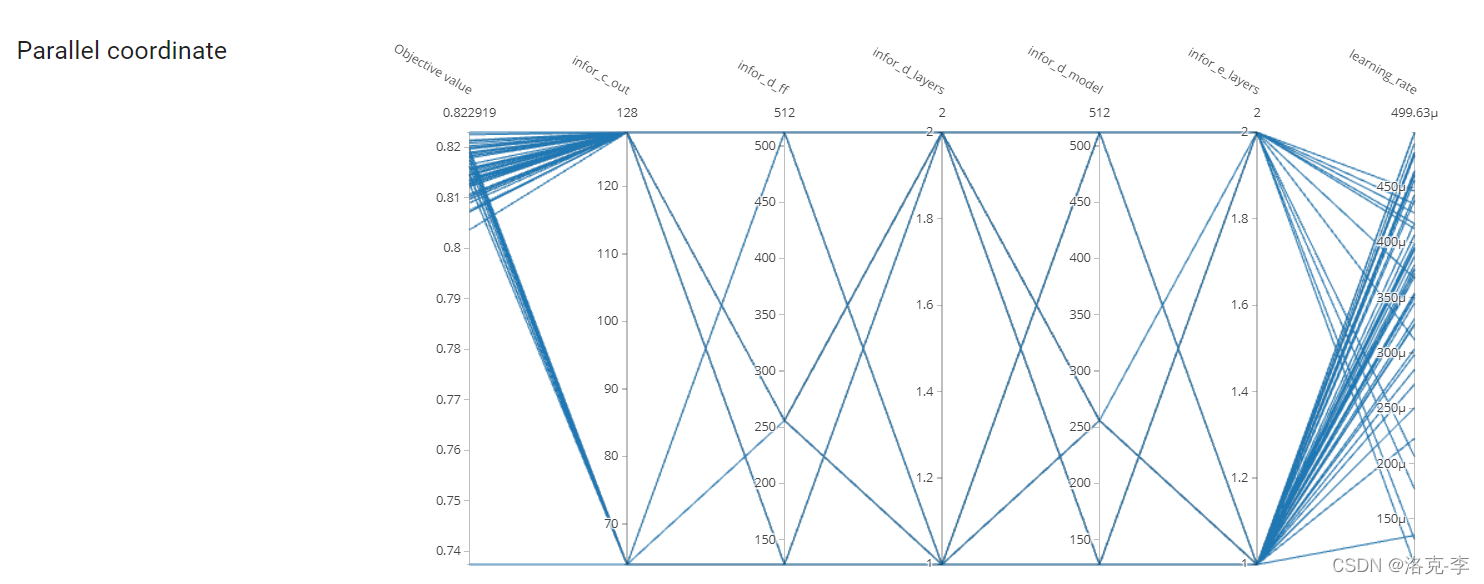
哪个参数比较重要: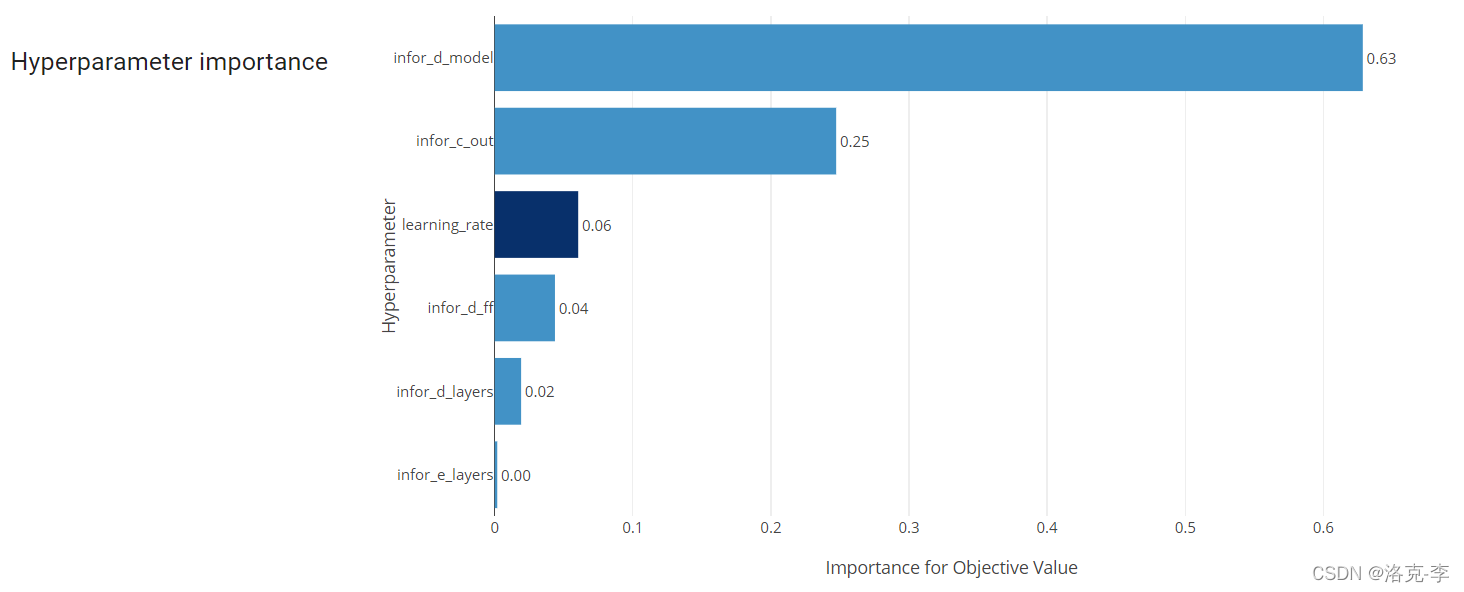

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)