
智能语音处理+1.5使用PocketSphinxshinx实现语音转文本(100%教会)
最后一章:智能语音处理+1.5使用PocketSphinxshinx实现语音转文本(100%教会)
欢迎来到智能语音处理系列的最后一篇文章,到这里,基本上语音处理是没问题了.
第一篇:智能语音处理+1.1下载需要的库(100%实现)-CSDN博客
第二篇:智能语音识别+1.2用SAPI实现文本转语音(100%教会)-CSDN博客
第三篇:智能语音处理+1.3用SpeechLib实现文本转语音(100%教会)-CSDN博客
第四篇:智能语音处理+1.4语音合成之输出英文音频文件(100%教会)-CSDN博客
哦对,差点忘了,这章的代码会用到一个库speechRecognition(语音识别的库)
pip install speechRecognition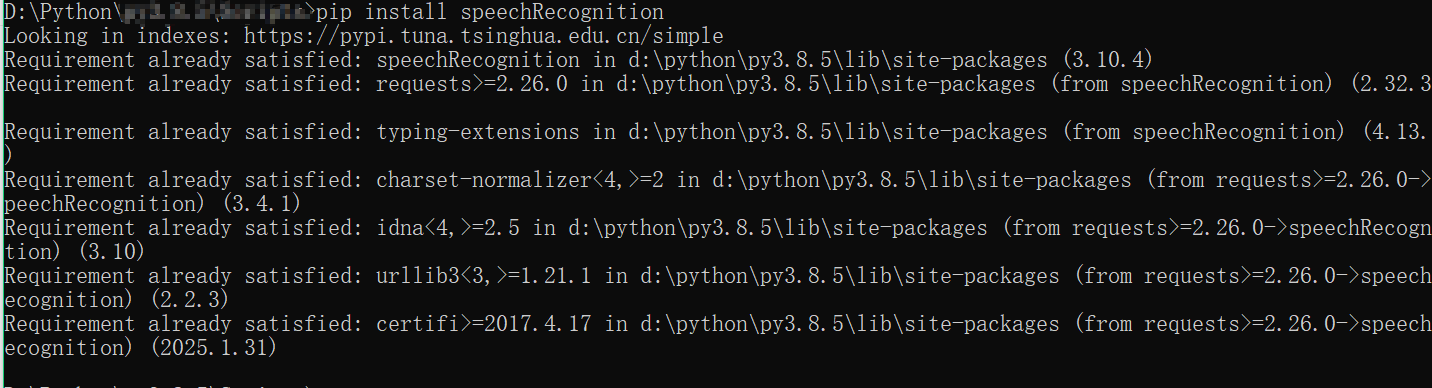
一.简单介绍 PocketSphinxshinx技术
PocketSphinx 是卡内基梅隆大学(CMU)开发的开源语音识别工具,是 CMU Sphinx 项目的轻量级版本,专为嵌入式设备和低资源环境(如移动端、IoT设备)优化。以下是其核心特点和技术细节:
| 特性 | 说明 |
|---|---|
| 轻量级 | 内存占用小(约4-16MB),适合移动端或低功耗设备(如树莓派)。 |
| 离线识别 | 无需网络连接,所有计算在本地完成,保护隐私。 |
| 可定制模型 | 支持自定义声学模型、语言模型和发音词典,适应特定场景(如关键词唤醒)。 |
| 实时性 | 低延迟识别,适合实时交互场景(如语音控制)。 |
| 跨平台 | 支持 Linux、Windows、Android、iOS 等系统。 |
PocketSphinx 技术简介
PocketSphinx 是卡内基梅隆大学(CMU)开发的开源语音识别工具,是 CMU Sphinx 项目的轻量级版本,专为嵌入式设备和低资源环境(如移动端、IoT设备)优化。以下是其核心特点和技术细节:
1. 核心特点
| 特性 | 说明 |
|---|---|
| 轻量级 | 内存占用小(约4-16MB),适合移动端或低功耗设备(如树莓派)。 |
| 离线识别 | 无需网络连接,所有计算在本地完成,保护隐私。 |
| 可定制模型 | 支持自定义声学模型、语言模型和发音词典,适应特定场景(如关键词唤醒)。 |
| 实时性 | 低延迟识别,适合实时交互场景(如语音控制)。 |
| 跨平台 | 支持 Linux、Windows、Android、iOS 等系统。 |
2. 技术原理
-
声学模型(Acoustic Model)
基于隐马尔可夫模型(HMM)或深度学习(如TDNN),将音频信号映射为音素(语音单元)。- 示例模型:
en-us(英语)、zh-cn(需自行训练或下载第三方模型)。
- 示例模型:
-
语言模型(Language Model)
定义词序列的概率分布(N-gram或神经网络),提升识别准确率。- 文件格式:
.lm(ARPA格式)或.DMP(二进制压缩格式)。
- 文件格式:
-
发音词典(Pronunciation Dictionary)
将词汇与其音素序列关联,例如:
你好 n i3 h ao3
世界 sh i4 j ie4
3. 应用场景
| 场景 | 案例 |
|---|---|
| 移动设备 | 离线语音助手、语音搜索(如Android应用)。 |
| 嵌入式系统 | 智能家居控制(如通过树莓派实现语音开关灯)。 |
| 教育/研究 | 语音识别算法教学、低成本语音交互原型开发。 |
| 低资源环境 | 无网络或弱网条件下的语音指令识别(如工业设备控制)。 |
4. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 完全开源且免费 | ❌ 中文官方模型质量较低,需自行优化或训练。 |
| ✅ 支持离线隐私保护 | ❌ 识别率低于云端API(如Google/百度)。 |
| ✅ 可深度定制模型 | ❌ 配置复杂(需处理声学/语言模型)。 |
二.完整代码及程序注释
okok,接下来你们去运行吧,拜拜,到此----智能语音处理系列完结!!!

# 导入语音识别库speech_recognition
import speech_recognition as sr # 官方文档:https://pypi.org/project/SpeechRecognition/
# 定义待识别的音频文件路径(需确保文件格式与引擎兼容,如WAV/PCM格式)
audio_file = 'demo_audio.wav'
# 创建识别器对象(内部默认使用CMU Sphinx引擎,但需单独安装语言模型)
r = sr.Recognizer()
# 打开音频文件并读取数据
with sr.AudioFile(audio_file) as source: # 自动处理文件打开和关闭
# 从音频源中提取全部音频数据(如果是长音频可用duration参数分段读取)
audio = r.record(source)
# 直接调用识别方法(存在严重问题:Sphinx引擎需独立安装中文模型且默认不支持中文!)
print('文本内容:', r.recognize_sphinx(audio, language="zh_CN"))
# try:
# # 错误1:recognize_sphinx的language="zh_CN"参数无效,Sphinx官方未提供简体中文模型
# print('文本内容:', r.recognize_sphinx(audio))
# # 错误2:不传language参数时默认使用英语模型,识别中文必然乱码
# print('文本内容:', r.recognize_sphinx(audio))
# except Exception as e:
# print(e)
技术共进,成长同行——讯飞AI开发者社区
更多推荐
 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)