
TensorFlow2学习六、对电影评论进行文本分类
一、本章目标使用keras和TensorFlow Hub分类器对电影评论进行分类,将影评分为积极、消极两类。这是一个机器学习中常见的二元分类问题。本章数据来源于网络电影数据库(Internet Movie Database)的 IMDB 数据集(IMDB dataset),其包含 50,000 条影评文本。从该数据集切割出的 25,000 条评论用作训练,另外 25,000 条用作测试。训练集..
一、本章目标
使用keras和TensorFlow Hub分类器对电影评论进行分类,将影评分为积极、消极两类。这是一个机器学习中常见的二元分类问题。
本章数据来源于网络电影数据库(Internet Movie Database)的 IMDB 数据集(IMDB dataset),其包含 50,000 条影评文本。从该数据集切割出的 25,000 条评论用作训练,另外 25,000 条用作测试。训练集与测试集是一样大,意味着它们包含相等数量的积极和消极评论。
二、过程
1. 导入库
from __future__ import absolute_import, division, print_function, unicode_literals
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print("GPU is", "available" if tf.config.experimental.list_physical_devices("GPU") else "NOT AVAILABLE")

2. 下载训练集
# 将训练集按照 6:4 的比例进行切割,从而最终我们将得到 15,000
# 个训练样本, 10,000 个验证样本以及 25,000 个测试样本
train_validation_split = tfds.Split.TRAIN.subsplit([6, 4])
(train_data, validation_data), test_data = tfds.load(
name="imdb_reviews",
split=(train_validation_split, tfds.Split.TEST),
as_supervised=True)

3. 查看数据格式
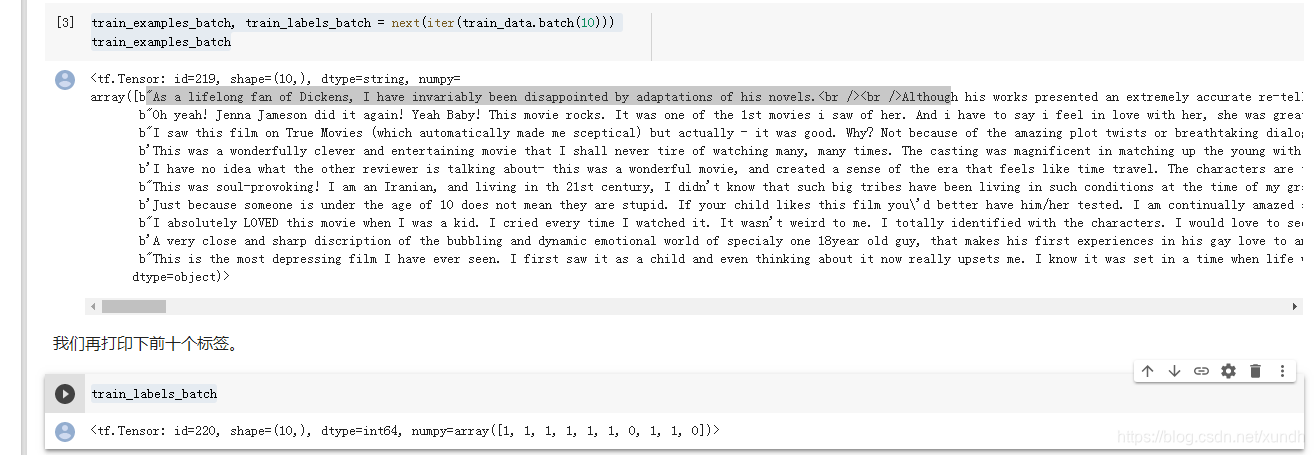
每一个样本都是一个表示电影评论和相应标签的句子。该句子不以任何方式进行预处理。
标签是一个值为 0 或 1 的整数,其中 0 代表消极评论,1 代表积极评论。
可以打印查看样本:
train_examples_batch, train_labels_batch = next(iter(train_data.batch(10)))
train_examples_batch
train_labels_batch
4. 构建模型
神经网络使用堆叠的层,重点要考虑:
- 如何表示文本
- 模型有多少层
- 每个层里有多少个隐层单元
首先需要将输入文本转换为嵌入向量。示例使用一个预先训练好的文本嵌入作为首层,这里采用TensorFlow Hub中名为google/tf2-preview/gnews-swivel-20dim/1 的一种预文本嵌入模型。本示例还有下面其它三种预训练模型可供测试:
- google/tf2-preview/gnews-swivel-20dim-with-oov/1 ——类似 google/tf2-preview/gnews-swivel-20dim/1,但 2.5%的词汇转换为未登录词桶(OOV buckets)。如果任务的词汇与模型的词汇没有完全重叠,这将会有所帮助。
- google/tf2-preview/nnlm-en-dim50/1 ——一个拥有约 1M 词汇量且维度为 50 的更大的模型。
- google/tf2-preview/nnlm-en-dim128/1 ——拥有约 1M 词汇量且维度为128的更大的模型。
i. 先构建一个TensorFlow Hub的Keras层,并在几个输入样本中测试,输出格式:(num_examples, embedding_dimension)
embedding = "https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1"
hub_layer = hub.KerasLayer(embedding, input_shape=[],
dtype=tf.string, trainable=True)
hub_layer(train_examples_batch[:3])

ii. 构建完整模型
model = tf.keras.Sequential()
model.add(hub_layer)
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()

层按顺序堆叠以构建分类器:
- 第一层是 Tensorflow Hub 层。这一层使用一个预训练的保存好的模型来将句子映射为嵌入向量(embedding vector)。我们所使用的预训练文本嵌入(embedding)模型(google/tf2-preview/gnews-swivel-20dim/1)将句子切割为符号,嵌入(embed)每个符号然后进行合并。最终得到的维度是:(num_examples, embedding_dimension)。
- 该定长输出向量通过一个有 16 个隐层单元的全连接层(Dense)进行管道传输。
- 最后一层与单个输出结点紧密相连。使用 Sigmoid 激活函数,其函数值为介于 0 与 1 之间的浮点数,表示概率或置信水平。
5. 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
一个模型需要损失函数和优化器来进行训练。
这是一个二分类问题且模型输出概率值(一个使用 sigmoid 激活函数的单一单元层),我们将使用 binary_crossentropy 损失函数。
6. 训练模型
以 512 个样本的 mini-batch 大小迭代 20 个 epoch 来训练模型。 这是指对 x_train 和 y_train 张量中所有样本的的 20 次迭代。在训练过程中,监测来自验证集的 10,000 个样本上的损失值(loss)和准确率(accuracy):
history = model.fit(train_data.shuffle(10000).batch(512),
epochs=20,
validation_data=validation_data.batch(512),
verbose=1)

7. 评估模型
results = model.evaluate(test_data.batch(512), verbose=2)
for name, value in zip(model.metrics_names, results):
print("%s: %.3f" % (name, value))
上面返回两个值:
- 损失值(loss,越小越好)
- 准确率


技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)