
012 大数据之HIVE查询
1、DBeaver连接HIVE查询实战1.1、HiveServer2的相关知识Hive架构之HiveServer2Prerequisites: Have Hive installed and setup to run on Hadoop cluster.HiveServer2 a.k.a HS2 is a second-generation Hive server that enables:① R
Language Manual
1、DBeaver连接HIVE查询实战
1.1、HiveServer2的相关知识
Hive架构之HiveServer2
Prerequisites: Have Hive installed and setup to run on Hadoop cluster.
HiveServer2 a.k.a HS2 is a second-generation Hive server that enables:
① Remote clients to execute queries against the Hive server;
② Multi-client concurrency and authentication;
③ Better supports for API client like JDBC and ODBC;
HiveServer2 Web UI: The Web UI is available at port 10002 (127.0.0.1:10002) by default.
Using Beeline CLI:beeline -u jdbc:hive2://127.0.0.1:10000 scott tiger
1.2、先启动hiveserver2
[atguigu@hadoop102 ~]$ hive --service hiveserver2
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/apache-zookeeper-3.5.7-bin/bin:/opt/module/apache-zookeeper-3.5.7-bin/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/apache-hive-3.1.2-bin/bin:/home/atguigu/.local/bin:/home/atguigu/bin)
2022-01-06 21:43:58: Starting HiveServer2
Hive Session ID = b97cbe6e-89e9-40ac-8aa7-c9a3ad520828
Hive Session ID = b2cb844b-cc3a-4b5a-b8e9-5fe8e3927bee
Hive Session ID = f1cf9d83-85ff-4706-8c41-b07b1b9736fb
Hive Session ID = 238898b4-2d09-486a-a916-eaea4c0c38db
beeline 执行SQL语句不打印INFO
[atguigu@hadoop102 ~]$ hive --service hiveserver2 --hiveconf hive.server2.logging.operation.level=NONE
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/apache-zookeeper-3.5.7-bin/bin:/opt/module/apache-zookeeper-3.5.7-bin/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/apache-hive-3.1.2-bin/bin:/home/atguigu/.local/bin:/home/atguigu/bin)
2022-01-06 22:48:13: Starting HiveServer2
Hive Session ID = b1f72f4e-1da5-496a-829b-9e38aae89306
Hive Session ID = 56beef0a-3792-42f3-aa93-427a436c85ae
Hive Session ID = 706d2870-2b2b-4437-a18a-3debbac17a3a
Hive Session ID = 9ec9ce6b-8cea-43e7-af0f-135116682fc1
[atguigu@hadoop102 ~]$ beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://hadoop102:10000> select true;
+-------+
| _c0 |
+-------+
| true |
+-------+
1 row selected (3.203 seconds)
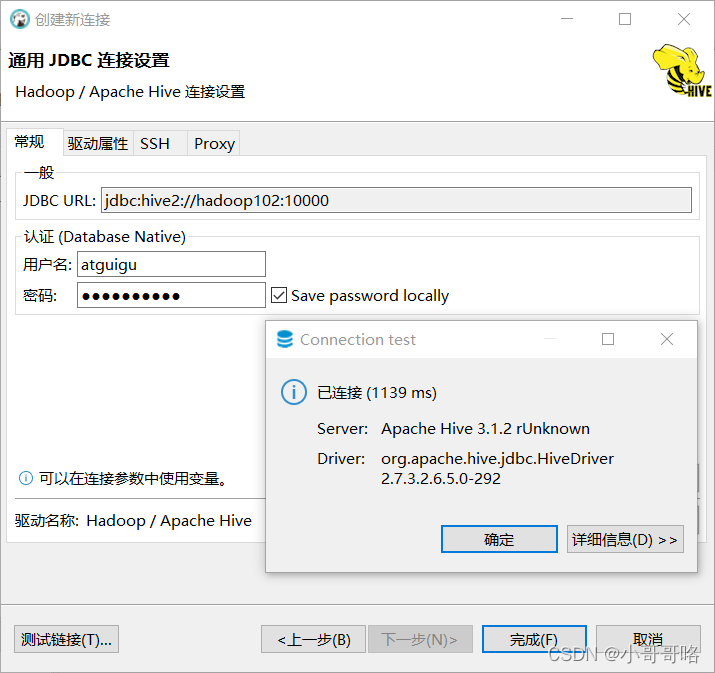
1.3、DBeaver安装好后填写连接信息,测试连通性
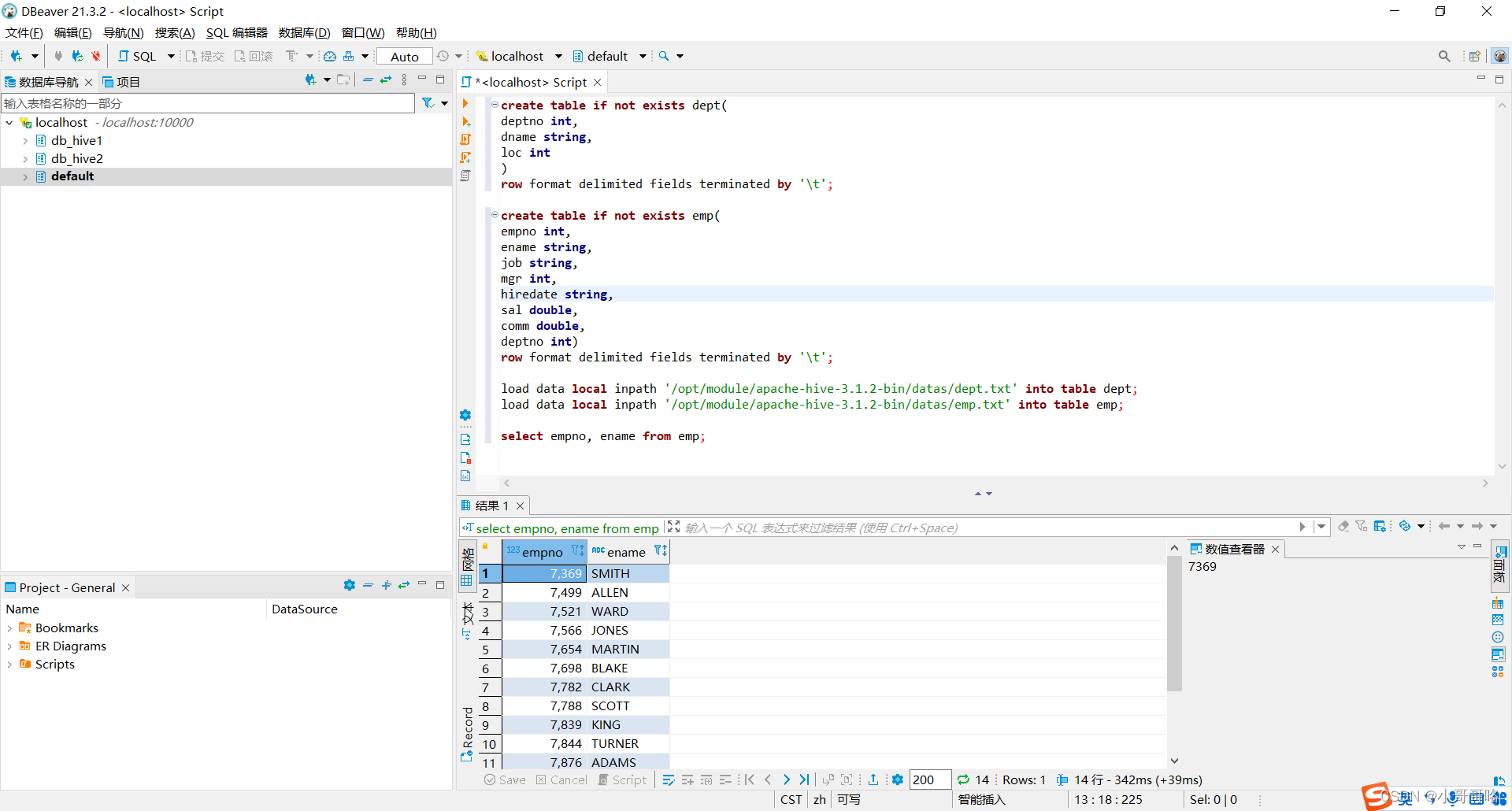
1.4、执行查询语句
# 其他双目运算符只要有一个参数为NULL则结果为NULL,<=>特殊对待
0: jdbc:hive2://hadoop102:10000> SELECT NULL<=>NULL;
+-------+
| _c0 |
+-------+
| true |
+-------+
1 row selected (0.161 seconds)
0: jdbc:hive2://hadoop102:10000> SELECT NULL<=>1;
+--------+
| _c0 |
+--------+
| false |
+--------+
1 row selected (0.137 seconds)
LIKE 表示模糊查询,RLIKE 可以使用Java的正则表达式来模糊查询
0: jdbc:hive2://hadoop102:10000> select * from emp where ename LIKE 'A%';
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
2 rows selected (0.252 seconds)
0: jdbc:hive2://hadoop102:10000> select * from emp where ename LIKE '_A%';
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
3 rows selected (0.197 seconds)
0: jdbc:hive2://hadoop102:10000> select * from emp where ename RLIKE '[A]';
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
7 rows selected (0.228 seconds)
1.5、每个Reduce内部排序(Sort By)
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by。
Sort by为每个Reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序。
0: jdbc:hive2://hadoop102:10000> select * from emp sort by deptno desc;
INFO : Compiling command(queryId=atguigu_20220109111856_cdd516ae-34f1-40f8-ab15-4a645864b571): select * from emp sort by deptno desc
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:emp.empno, type:int, comment:null), FieldSchema(name:emp.ename, type:string, comment:null), FieldSchema(name:emp.job, type:string, comment:null), FieldSchema(name:emp.mgr, type:int, comment:null), FieldSchema(name:emp.hiredate, type:string, comment:null), FieldSchema(name:emp.sal, type:double, comment:null), FieldSchema(name:emp.comm, type:double, comment:null), FieldSchema(name:emp.deptno, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109111856_cdd516ae-34f1-40f8-ab15-4a645864b571); Time taken: 0.075 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109111856_cdd516ae-34f1-40f8-ab15-4a645864b571): select * from emp sort by deptno desc
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = atguigu_20220109111856_cdd516ae-34f1-40f8-ab15-4a645864b571
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1641212039494_0012
INFO : Executing with tokens: []
INFO : The url to track the job: http://hadoop103:8088/proxy/application_1641212039494_0012/
INFO : Starting Job = job_1641212039494_0012, Tracking URL = http://hadoop103:8088/proxy/application_1641212039494_0012/
INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1641212039494_0012
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2022-01-09 11:19:04,920 Stage-1 map = 0%, reduce = 0%
INFO : 2022-01-09 11:19:10,144 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.96 sec
INFO : 2022-01-09 11:19:18,323 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.51 sec
INFO : MapReduce Total cumulative CPU time: 5 seconds 510 msec
INFO : Ended Job = job_1641212039494_0012
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.51 sec HDFS Read: 13431 HDFS Write: 916 SUCCESS
INFO : Total MapReduce CPU Time Spent: 5 seconds 510 msec
INFO : Completed executing command(queryId=atguigu_20220109111856_cdd516ae-34f1-40f8-ab15-4a645864b571); Time taken: 24.003 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
14 rows selected (24.123 seconds)
0: jdbc:hive2://hadoop102:10000> set mapreduce.job.reduces;
+---------------------------+
| set |
+---------------------------+
| mapreduce.job.reduces=-1 |
+---------------------------+
1 row selected (0.012 seconds)
0: jdbc:hive2://hadoop102:10000> set mapreduce.job.reduces=3;
No rows affected (0.005 seconds)
0: jdbc:hive2://hadoop102:10000> set mapreduce.job.reduces;
+--------------------------+
| set |
+--------------------------+
| mapreduce.job.reduces=3 |
+--------------------------+
1 row selected (0.01 seconds)
0: jdbc:hive2://hadoop102:10000> select * from emp sort by deptno desc;
INFO : Compiling command(queryId=atguigu_20220109112004_21cd98fa-a0bb-49a7-91b4-1dc37093eba1): select * from emp sort by deptno desc
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:emp.empno, type:int, comment:null), FieldSchema(name:emp.ename, type:string, comment:null), FieldSchema(name:emp.job, type:string, comment:null), FieldSchema(name:emp.mgr, type:int, comment:null), FieldSchema(name:emp.hiredate, type:string, comment:null), FieldSchema(name:emp.sal, type:double, comment:null), FieldSchema(name:emp.comm, type:double, comment:null), FieldSchema(name:emp.deptno, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109112004_21cd98fa-a0bb-49a7-91b4-1dc37093eba1); Time taken: 0.065 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109112004_21cd98fa-a0bb-49a7-91b4-1dc37093eba1): select * from emp sort by deptno desc
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = atguigu_20220109112004_21cd98fa-a0bb-49a7-91b4-1dc37093eba1
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks not specified. Defaulting to jobconf value of: 3
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1641212039494_0013
INFO : Executing with tokens: []
INFO : The url to track the job: http://hadoop103:8088/proxy/application_1641212039494_0013/
INFO : Starting Job = job_1641212039494_0013, Tracking URL = http://hadoop103:8088/proxy/application_1641212039494_0013/
INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1641212039494_0013
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
INFO : 2022-01-09 11:20:14,771 Stage-1 map = 0%, reduce = 0%
INFO : 2022-01-09 11:20:22,123 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.21 sec
INFO : 2022-01-09 11:20:29,452 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 12.65 sec
INFO : MapReduce Total cumulative CPU time: 12 seconds 650 msec
INFO : Ended Job = job_1641212039494_0013
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 12.65 sec HDFS Read: 26621 HDFS Write: 1090 SUCCESS
INFO : Total MapReduce CPU Time Spent: 12 seconds 650 msec
INFO : Completed executing command(queryId=atguigu_20220109112004_21cd98fa-a0bb-49a7-91b4-1dc37093eba1); Time taken: 27.011 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
14 rows selected (27.132 seconds)
# 执行SQL的过程中每个reducer处理的最大字节数量
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
# 设置Hive的最大reducer数量
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
# 设定Hive的reduce数量
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
set mapreduce.job.reduces=number 优先级最高
set hive.exec.reducers.max=number 优先级次之
set hive.exec.reducers.bytes.per.reducer=number 优先级最低
PS:从hive 0.14开始,一个reducer处理文件的大小的默认值是256M。
set mapreduce.job.reduces没有设置时,reduce计算方式:
reduceNum=min(hive.exec.reducers.max,map输出数据量/hive.exec.reducers.bytes.per.reducer)
1.6、分区(Distribute By)
DISTRIBUTE BY的分区规则是根据分区字段的HASH码与REDUCE的个数进行模除后,余数相同的分到一个区,结合SORT BY使用,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
0: jdbc:hive2://hadoop102:10000> set mapreduce.job.reduces = 3;
No rows affected (0.013 seconds)
0: jdbc:hive2://hadoop102:10000> select * from emp distribute by deptno sort by empno desc;
INFO : Compiling command(queryId=atguigu_20220109170205_8fa3fe58-e759-4051-8357-45b580574568): select * from emp distribute by deptno sort by empno desc
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:emp.empno, type:int, comment:null), FieldSchema(name:emp.ename, type:string, comment:null), FieldSchema(name:emp.job, type:string, comment:null), FieldSchema(name:emp.mgr, type:int, comment:null), FieldSchema(name:emp.hiredate, type:string, comment:null), FieldSchema(name:emp.sal, type:double, comment:null), FieldSchema(name:emp.comm, type:double, comment:null), FieldSchema(name:emp.deptno, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109170205_8fa3fe58-e759-4051-8357-45b580574568); Time taken: 0.086 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109170205_8fa3fe58-e759-4051-8357-45b580574568): select * from emp distribute by deptno sort by empno desc
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = atguigu_20220109170205_8fa3fe58-e759-4051-8357-45b580574568
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks not specified. Defaulting to jobconf value of: 3
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1641212039494_0016
INFO : Executing with tokens: []
INFO : The url to track the job: http://hadoop103:8088/proxy/application_1641212039494_0016/
INFO : Starting Job = job_1641212039494_0016, Tracking URL = http://hadoop103:8088/proxy/application_1641212039494_0016/
INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1641212039494_0016
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
INFO : 2022-01-09 17:02:15,697 Stage-1 map = 0%, reduce = 0%
INFO : 2022-01-09 17:02:22,952 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.15 sec
INFO : 2022-01-09 17:02:30,301 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 7.67 sec
INFO : 2022-01-09 17:02:31,334 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 14.09 sec
INFO : MapReduce Total cumulative CPU time: 14 seconds 90 msec
INFO : Ended Job = job_1641212039494_0016
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 14.09 sec HDFS Read: 26708 HDFS Write: 1090 SUCCESS
INFO : Total MapReduce CPU Time Spent: 14 seconds 90 msec
INFO : Completed executing command(queryId=atguigu_20220109170205_8fa3fe58-e759-4051-8357-45b580574568); Time taken: 26.545 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
14 rows selected (26.702 seconds)
当distribute by和sort by字段相同时,可以使用cluster by方式,但cluster by只能是升序排序。
0: jdbc:hive2://hadoop102:10000> select * from emp distribute by deptno sort by deptno;
0: jdbc:hive2://hadoop102:10000> select * from emp cluster by deptno;
2、分区表(partitioned by)和分桶表
Hive中的分区就是分目录,各文件夹下是对应分区所有的数据文件,查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。建表后,可以单独增加、删除一个或多个分区。
注意:分区字段(可以多级分区)不能是表中已经存在的数据,可以将分区字段看作表的伪列。
2.1、显示分区表信息
0: jdbc:hive2://hadoop102:10000> show partitions dept_partition2;
INFO : Compiling command(queryId=atguigu_20220109172721_82fe29a5-5c2c-4df9-88e8-95b5f61ba66d): show partitions dept_partition2
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:partition, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109172721_82fe29a5-5c2c-4df9-88e8-95b5f61ba66d); Time taken: 0.096 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109172721_82fe29a5-5c2c-4df9-88e8-95b5f61ba66d): show partitions dept_partition2
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=atguigu_20220109172721_82fe29a5-5c2c-4df9-88e8-95b5f61ba66d); Time taken: 0.056 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-----------------------+
| partition |
+-----------------------+
| day=20200401/hour=12 |
+-----------------------+
1 row selected (0.181 seconds)
0: jdbc:hive2://hadoop102:10000> desc formatted dept_partition1;
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Table not found dept_partition1 (state=42S02,code=10001)
0: jdbc:hive2://hadoop102:10000> desc formatted dept_partition2;
INFO : Compiling command(queryId=atguigu_20220109172816_7fb3f821-e5a6-48bb-ba71-3c587db79a9c): desc formatted dept_partition2
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col_name, type:string, comment:from deserializer), FieldSchema(name:data_type, type:string, comment:from deserializer), FieldSchema(name:comment, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109172816_7fb3f821-e5a6-48bb-ba71-3c587db79a9c); Time taken: 0.073 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109172816_7fb3f821-e5a6-48bb-ba71-3c587db79a9c): desc formatted dept_partition2
INFO : Starting task [Stage-0:DDL] in serial mode
+-------------------------------+----------------------------------------------------+-----------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-----------------------+
| # col_name | data_type | comment |
| deptno | int | |
| dname | string | |
| loc | string | |
| | NULL | NULL |
| # Partition Information | NULL | NULL |
| # col_name | data_type | comment |
| day | string | |
| hour | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | default | NULL |
| OwnerType: | USER | NULL |
| Owner: | atguigu | NULL |
| CreateTime: | Sun Jan 09 17:22:59 CST 2022 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://hadoop102:9820/user/hive/warehouse/dept_partition2 | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | bucketing_version | 2 |
| | numFiles | 9 |
| | numPartitions | 1 |
| | numRows | 0 |
| | rawDataSize | 0 |
| | totalSize | 1171 |
| | transient_lastDdlTime | 1641720179 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | \t |
| | serialization.format | \t |
+-------------------------------+----------------------------------------------------+-----------------------+
39 rows selected (0.244 seconds)
INFO : Completed executing command(queryId=atguigu_20220109172816_7fb3f821-e5a6-48bb-ba71-3c587db79a9c); Time taken: 0.134 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
2.2、加载数据到分区中的方法
把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
方式一:上传数据后修复
0: jdbc:hive2://hadoop102:10000> dfs -mkdir -p /user/hive/warehouse/dept_partition2/day=20200401/hour=13;
+-------------+
| DFS Output |
+-------------+
+-------------+
No rows selected (0.085 seconds)
0: jdbc:hive2://hadoop102:10000> dfs -put /opt/module/apache-hive-3.1.2-bin/datas/dept_20200402.log /user/hive/warehouse/dept_partition2/day=20200401/hour=13;
+-------------+
| DFS Output |
+-------------+
+-------------+
No rows selected (0.071 seconds)
0: jdbc:hive2://hadoop102:10000> select * from dept_partition2 where day='20200401' and hour='13';
INFO : Compiling command(queryId=atguigu_20220109173435_6ee95f18-3adb-4f08-b32b-aaa4e55a41a9): select * from dept_partition2 where day='20200401' and hour='13'
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:dept_partition2.deptno, type:int, comment:null), FieldSchema(name:dept_partition2.dname, type:string, comment:null), FieldSchema(name:dept_partition2.loc, type:string, comment:null), FieldSchema(name:dept_partition2.day, type:string, comment:null), FieldSchema(name:dept_partition2.hour, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109173435_6ee95f18-3adb-4f08-b32b-aaa4e55a41a9); Time taken: 0.203 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109173435_6ee95f18-3adb-4f08-b32b-aaa4e55a41a9): select * from dept_partition2 where day='20200401' and hour='13'
INFO : Completed executing command(queryId=atguigu_20220109173435_6ee95f18-3adb-4f08-b32b-aaa4e55a41a9); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
| dept_partition2.deptno | dept_partition2.dname | dept_partition2.loc | dept_partition2.day | dept_partition2.hour |
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
No rows selected (0.222 seconds)
0: jdbc:hive2://hadoop102:10000> msck repair table dept_partition2;
INFO : Compiling command(queryId=atguigu_20220109173502_71cec345-f1b8-4342-b79e-e53b80bea0b7): msck repair table dept_partition2
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109173502_71cec345-f1b8-4342-b79e-e53b80bea0b7); Time taken: 0.044 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109173502_71cec345-f1b8-4342-b79e-e53b80bea0b7): msck repair table dept_partition2
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=atguigu_20220109173502_71cec345-f1b8-4342-b79e-e53b80bea0b7); Time taken: 0.167 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.227 seconds)
0: jdbc:hive2://hadoop102:10000> select * from dept_partition2 where day='20200401' and hour='13';
INFO : Compiling command(queryId=atguigu_20220109173507_9ec04907-727e-469a-aee5-79006c45fd02): select * from dept_partition2 where day='20200401' and hour='13'
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:dept_partition2.deptno, type:int, comment:null), FieldSchema(name:dept_partition2.dname, type:string, comment:null), FieldSchema(name:dept_partition2.loc, type:string, comment:null), FieldSchema(name:dept_partition2.day, type:string, comment:null), FieldSchema(name:dept_partition2.hour, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109173507_9ec04907-727e-469a-aee5-79006c45fd02); Time taken: 0.196 seconds
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
| dept_partition2.deptno | dept_partition2.dname | dept_partition2.loc | dept_partition2.day | dept_partition2.hour |
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
| 30 | SALES | 1900 | 20200401 | 13 |
| 40 | OPERATIONS | 1700 | 20200401 | 13 |
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
2 rows selected (0.23 seconds)
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109173507_9ec04907-727e-469a-aee5-79006c45fd02): select * from dept_partition2 where day='20200401' and hour='13'
INFO : Completed executing command(queryId=atguigu_20220109173507_9ec04907-727e-469a-aee5-79006c45fd02); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
方式二:上传数据后添加分区
0: jdbc:hive2://hadoop102:10000> dfs -mkdir -p /user/hive/warehouse/dept_partition2/day=20200401/hour=14;
+-------------+
| DFS Output |
+-------------+
+-------------+
No rows selected (0.036 seconds)
0: jdbc:hive2://hadoop102:10000> dfs -put /opt/module/apache-hive-3.1.2-bin/datas/dept_20200402.log /user/hive/warehouse/dept_partition2/day=20200401/hour=14;
+-------------+
| DFS Output |
+-------------+
+-------------+
No rows selected (0.068 seconds)
0: jdbc:hive2://hadoop102:10000> alter table dept_partition2 add partition(day='20200401',hour='14');
INFO : Compiling command(queryId=atguigu_20220109173948_564a03ef-f161-4f2d-9700-d81ef5b68e1f): alter table dept_partition2 add partition(day='20200401',hour='14')
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109173948_564a03ef-f161-4f2d-9700-d81ef5b68e1f); Time taken: 0.056 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109173948_564a03ef-f161-4f2d-9700-d81ef5b68e1f): alter table dept_partition2 add partition(day='20200401',hour='14')
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=atguigu_20220109173948_564a03ef-f161-4f2d-9700-d81ef5b68e1f); Time taken: 0.084 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.156 seconds)
0: jdbc:hive2://hadoop102:10000> select * from dept_partition2 where day='20200401' and hour='14';
INFO : Compiling command(queryId=atguigu_20220109174004_71affc09-6697-40c7-93fd-d705827e629a): select * from dept_partition2 where day='20200401' and hour='14'
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:dept_partition2.deptno, type:int, comment:null), FieldSchema(name:dept_partition2.dname, type:string, comment:null), FieldSchema(name:dept_partition2.loc, type:string, comment:null), FieldSchema(name:dept_partition2.day, type:string, comment:null), FieldSchema(name:dept_partition2.hour, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109174004_71affc09-6697-40c7-93fd-d705827e629a); Time taken: 0.211 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109174004_71affc09-6697-40c7-93fd-d705827e629a): select * from dept_partition2 where day='20200401' and hour='14'
INFO : Completed executing command(queryId=atguigu_20220109174004_71affc09-6697-40c7-93fd-d705827e629a); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
| dept_partition2.deptno | dept_partition2.dname | dept_partition2.loc | dept_partition2.day | dept_partition2.hour |
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
| 30 | SALES | 1900 | 20200401 | 14 |
| 40 | OPERATIONS | 1700 | 20200401 | 14 |
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
2 rows selected (0.261 seconds)
方式三:创建文件夹后load数据到分区
0: jdbc:hive2://hadoop102:10000> load data local inpath '/opt/module/apache-hive-3.1.2-bin/datas/dept_20200401.log' into table dept_partition2 partition(day='20200401',hour='16');
INFO : Compiling command(queryId=atguigu_20220109174247_e87bdbd6-209e-42aa-b574-805611ee23b9): load data local inpath '/opt/module/apache-hive-3.1.2-bin/datas/dept_20200401.log' into table dept_partition2 partition(day='20200401',hour='16')
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109174247_e87bdbd6-209e-42aa-b574-805611ee23b9); Time taken: 0.085 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109174247_e87bdbd6-209e-42aa-b574-805611ee23b9): load data local inpath '/opt/module/apache-hive-3.1.2-bin/datas/dept_20200401.log' into table dept_partition2 partition(day='20200401',hour='16')
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table default.dept_partition2 partition (day=20200401, hour=16) from file:/opt/module/apache-hive-3.1.2-bin/datas/dept_20200401.log
INFO : Starting task [Stage-1:STATS] in serial mode
INFO : Completed executing command(queryId=atguigu_20220109174247_e87bdbd6-209e-42aa-b574-805611ee23b9); Time taken: 0.322 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.427 seconds)
0: jdbc:hive2://hadoop102:10000> select * from dept_partition2 where day='20200401' and hour='16';
INFO : Compiling command(queryId=atguigu_20220109174304_4dbe1070-c681-4a26-afe9-01e08108468e): select * from dept_partition2 where day='20200401' and hour='16'
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:dept_partition2.deptno, type:int, comment:null), FieldSchema(name:dept_partition2.dname, type:string, comment:null), FieldSchema(name:dept_partition2.loc, type:string, comment:null), FieldSchema(name:dept_partition2.day, type:string, comment:null), FieldSchema(name:dept_partition2.hour, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109174304_4dbe1070-c681-4a26-afe9-01e08108468e); Time taken: 0.18 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109174304_4dbe1070-c681-4a26-afe9-01e08108468e): select * from dept_partition2 where day='20200401' and hour='16'
INFO : Completed executing command(queryId=atguigu_20220109174304_4dbe1070-c681-4a26-afe9-01e08108468e); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
| dept_partition2.deptno | dept_partition2.dname | dept_partition2.loc | dept_partition2.day | dept_partition2.hour |
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
| 10 | ACCOUNTING | 1700 | 20200401 | 16 |
| 20 | RESEARCH | 1800 | 20200401 | 16 |
+-------------------------+------------------------+----------------------+----------------------+-----------------------+
2 rows selected (0.211 seconds)
2.3、动态分区
# 动态分区默认开启
0: jdbc:hive2://hadoop102:10000> set hive.exec.dynamic.partition;
+-----------------------------------+
| set |
+-----------------------------------+
| hive.exec.dynamic.partition=true |
+-----------------------------------+
1 row selected (0.028 seconds)
# 默认strict,表示必须指定至少一个分区为静态分区
0: jdbc:hive2://hadoop102:10000> set hive.exec.dynamic.partition.mode;
+------------------------------------------+
| set |
+------------------------------------------+
| hive.exec.dynamic.partition.mode=strict |
+------------------------------------------+
1 row selected (0.01 seconds)
# nonstrict模式表示允许所有的分区字段都可以使用动态分区
0: jdbc:hive2://hadoop102:10000> set hive.exec.dynamic.partition.mode=nonstrict;
No rows affected (0.005 seconds)
# 在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。
0: jdbc:hive2://hadoop102:10000> set hive.exec.max.dynamic.partitions;
+----------------------------------------+
| set |
+----------------------------------------+
| hive.exec.max.dynamic.partitions=1000 |
+----------------------------------------+
1 row selected (0.009 seconds)
# 动态分区字段的可能分区数大于100时,会报错,根据实际情况设定
# 在每个执行 MR 的节点上,最大可以创建多少个动态分区
0: jdbc:hive2://hadoop102:10000> set hive.exec.max.dynamic.partitions.pernode;
+-----------------------------------------------+
| set |
+-----------------------------------------------+
| hive.exec.max.dynamic.partitions.pernode=100 |
+-----------------------------------------------+
1 row selected (0.014 seconds)
# 整个 MR Job 中,最大可以创建多少个 HDFS 文件。
0: jdbc:hive2://hadoop102:10000> set hive.exec.max.created.files;
+-------------------------------------+
| set |
+-------------------------------------+
| hive.exec.max.created.files=100000 |
+-------------------------------------+
1 row selected (0.011 seconds)
# 当有空分区生成时,是否抛出异常。一般不需要设置。
0: jdbc:hive2://hadoop102:10000> set hive.error.on.empty.partition;
+--------------------------------------+
| set |
+--------------------------------------+
| hive.error.on.empty.partition=false |
+--------------------------------------+
1 row selected (0.014 seconds)
2.4、分桶表
对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。分区针对的是数据文件的存储路径,分桶针对的是数据文件。
注意:Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
直接使用 Load 语句向分桶表加载数据,数据时可以加载成功的,但是数据并不会分桶。这是由于分桶的实质是对指定字段做了 hash 散列然后存放到对应文件中,这意味着向分桶表中插入数据是必然要通过 MapReduce,且 Reducer 的数量必须等于分桶的数量。由于以上原因,分桶表的数据通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因为 CTAS 操作会触发 MapReduce。
分区表和分桶表的本质都是将数据按照不同粒度进行拆分,从而使得在查询时候不必扫描全表,只需要扫描对应的分区或分桶,从而提升查询效率。两者可以结合起来使用,从而保证表数据在不同粒度上都能得到合理的拆分。下面是 Hive 官方给出的示例:
CREATE TABLE page_view_bucketed(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING )
PARTITIONED BY(dt STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
此时导入数据时需要指定分区:
INSERT OVERWRITE page_view_bucketed
PARTITION (dt='2009-02-25')
SELECT * FROM page_view WHERE dt='2009-02-25';
2.5、抽样查询
随机分桶抽样: 含义是在emp表中选取满足where条件数据,按分桶随机抽样取1/4的量。(得到的数据大概是符合条件数据的1/4,但是并不是严格的1/4).
0: jdbc:hive2://hadoop102:10000> select * from emp tablesample(bucket 1 out of 4 on empno);
INFO : Compiling command(queryId=atguigu_20220109183951_76d58610-85ca-4420-94cb-9096ff37148f): select * from emp tablesample(bucket 1 out of 4 on empno)
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:emp.empno, type:int, comment:null), FieldSchema(name:emp.ename, type:string, comment:null), FieldSchema(name:emp.job, type:string, comment:null), FieldSchema(name:emp.mgr, type:int, comment:null), FieldSchema(name:emp.hiredate, type:string, comment:null), FieldSchema(name:emp.sal, type:double, comment:null), FieldSchema(name:emp.comm, type:double, comment:null), FieldSchema(name:emp.deptno, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220109183951_76d58610-85ca-4420-94cb-9096ff37148f); Time taken: 0.094 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220109183951_76d58610-85ca-4420-94cb-9096ff37148f): select * from emp tablesample(bucket 1 out of 4 on empno)
INFO : Completed executing command(queryId=atguigu_20220109183951_76d58610-85ca-4420-94cb-9096ff37148f); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
7 rows selected (0.147 seconds)
数据块抽样:从符合where条件筛选的数据中抽取百分之10的数据。
0: jdbc:hive2://hadoop102:10000> select * from emp tablesample(10 PERCENT);
INFO : Compiling command(queryId=atguigu_20220703221129_6d85c130-2338-43cb-979e-cb249351220d): select * from emp tablesample(10 PERCENT)
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:emp.empno, type:int, comment:null), FieldSchema(name:emp.ename, type:string, comment:null), FieldSchema(name:emp.job, type:string, comment:null), FieldSchema(name:emp.mgr, type:int, comment:null), FieldSchema(name:emp.hiredate, type:string, comment:null), FieldSchema(name:emp.sal, type:double, comment:null), FieldSchema(name:emp.comm, type:double, comment:null), FieldSchema(name:emp.deptno, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=atguigu_20220703221129_6d85c130-2338-43cb-979e-cb249351220d); Time taken: 0.086 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=atguigu_20220703221129_6d85c130-2338-43cb-979e-cb249351220d): select * from emp tablesample(10 PERCENT)
INFO : Completed executing command(queryId=atguigu_20220703221129_6d85c130-2338-43cb-979e-cb249351220d); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
+------------+------------+-----------+----------+---------------+----------+-----------+-------------+
2 rows selected (0.15 seconds)
3、函数
# 查看系统自带的函数
hive> show functions;
# 显示自带的函数的用法
hive> desc function upper;
# 详细显示自带的函数的用法
hive> desc function extended upper;
LanguageManual Windowing And Analytics
对hive开窗函数 over中的partition by与group by理解
Hive 开窗函数
Hive开窗函数
Hive开窗函数整理
Hive系列 (四):自定义函数UDF UDTF UDAF
Hive3.1.2版本的UDF开发教程
Hive的UDF编程-GenericUDF编程
Hive 自定义 UDTF 函数

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)