
基于IoU的单级目标检测算法
IoU-aware Single-stage Object Detector for Accurate LocalizationShengkai Wua, Xiaoping Lia,∗, Xinggang WangbaState Key Laboratory of Digital Manufacturing Equipment and Technology, HuazhongUnivers...
IoU-aware Single-stage Object Detector for Accurate Localization
Shengkai Wua, Xiaoping Lia,∗, Xinggang Wangb
aState Key Laboratory of Digital Manufacturing Equipment and Technology, Huazhong
University of Science and Technology, Wuhan, 430074, China.
bSchool of EIC, Huazhong University of Science and Technology, Wuhan, 430074, China.
Abstract
单级目标检测器以其简单高效的特点,在计算机视觉领域得到了广泛的应用。然而,由于分类得分与预测检测的定位精度相关性不高,严重影响了模型的定位精度。本文提出了一种基于IoU的单级目标检测方法。具体来说,IoU感知的单级目标检测器预测回归盒和地面真值盒之间的IoU。然后将分类得分与预测的IoU相乘,计算出与定位精度高度相关的检测置信度。利用检测置信度作为NMS和COCO-AP计算的输入,将大大提高模型的定位精度。在COCO和PASCAL-VOC数据集上的大量实验表明,基于IoU的单级目标检测在提高定位精度方面是有效的。在没有口哨声和钟声的情况下,与基线相比,该方法在COCO测试dev和PASCAL VOC2007测试中的AP分别提高了1.0%和1.1%和2.2%。IoU阈值较高(0.7∼0.9)时,COCO测试设备的AP改善率为1.7%∼2.3%,PASCAL VOC2007测试设备的AP改善率为1.0%∼4.2%。源代码将公开提供。
关键词:IoU预测,IoU感知检测器,精确定位,分类得分与定位精度的相关性
1. Introduction
随着深卷积神经网络的发展,近年来提出了大量的目标检测模型。这些模型大多可分为单级目标探测器[1、2、3、4、5、6]和多级目标探测器[7、8、9、10、11、12、13]。对于多级目标检测器,采用了多级分类和定位的方法,使得这些模型在分类和定位任务上具有更强的能力。与单级目标检测器相比,多级目标检测器具有更好的平均精度(AP),但多级分类和定位子网的存在会影响检测效率。相反,单级检测器依靠完全卷积网络(FCN)进行分类和定位,更加简单有效。然而,单级探测器的AP通常落后于多级探测器。
本文旨在提高单级探测器的AP,同时保持其效率。结果表明,单级检测器的分类分数与定位精度之间的低相关性严重影响了模型的定位精度。低相关性的主要原因是分类子网和定位子网在没有明确相互了解的情况下,使用独立的目标函数进行训练。在模型收敛后,分类子网在不知道定位精度的情况下预测每个回归锚的分类得分,用回归锚与地面真值盒之间的IoU表示。因此,会有很多检测结果存在分类分数与其定位精度不匹配的问题,例如分类分数高但IoU低的检测,分类分数低但IoU高的检测。在推理过程中,这些检测会从两个方面影响模型的定位精度。首先,在标准非最大抑制(NMS)中,所有检测都基于它们的分类分数进行排序,并且具有较高分类分数的检测将抑制与阈值重叠的其他检测。因此,分类分数高但IoU高的检测将被分类分数高但IoU低的检测所抑制。其次,在计算平均精度(AP)的过程中,所有的检测结果也会根据其分类得分进行排序。为了计算平均精度,根据这些排序的检测结果计算精度和召回率,如果在分类分数低但IoU高的检测结果之前,分类分数高但IoU等级低的检测结果,IoU阈值高的检测结果精度会降低,从而导致IoU阈值高的AP值降低。这两个问题都会影响模型的定位精度。
为了解决上述问题,我们提出了基于RetinaNet的IoU感知单级目标检测算法[3]。将与回归头平行的IoU预测头附加到回归分支的最后一层,以预测每个回归锚的IoU。在训练过程中,IoU预测头与分类头、定位头共同训练。在推理过程中,通过将每个检测框的分类得分和预测IoU相乘来计算检测置信度,然后用于在随后的NMS和AP计算中对所有检测进行排序。由于检测置信度与定位精度高度相关,可以解决上述问题,从而如实验所示,大大提高模型的定位精度。
本文的其余部分安排如下。第二节介绍了相关的研究工作。第三节详细介绍了基于IoU的单级目标检测器。第四节在COCO和PASCAL的VOC数据集上进行了大量的实验,证明了该方法的有效性。第5节给出结论。
2. Related Work
分类得分与定位精度的相关性。分类得分与定位精度之间的低相关性严重影响了模型的定位精度,为此提出了多种方法。适应度NMS[14]通过将定位精度划分为5个级别,并将定位精度预测任务转化为分类任务,改进了DeNet[15]。在推理过程中,将每个检测盒的适应度计算为预测适应度概率的加权和,然后与分类得分相乘,作为与定位精度相关性较大的最终检测得分。然后将此分数作为网络管理系统的输入,表示为适应度网络管理系统,以提高DeNet的定位精度。IoU网[16]通过设计与R-CNN并行的IoU预测头来预测每个RoI的回归IoU,提高了R-CNN的速度[7]。在推理过程中,根据预测的IoU对检测到的3个盒子进行排序,然后采用IoUguided NMS提高定位精度。类似地,MS R-CNN[17]通过将Mask IoU头与掩模头平行地附加在掩模R-CNN[9]上以预测预测掩模和相应地面真值掩模之间的IoU来改进掩模R-CNN[9]。在推理过程中,将预测的IoU与分类得分相乘作为最终的掩模置信度,然后用于计算AP时对预测的掩模进行排序。所有这些方法都设计了额外的子网来预测定位精度,并应用于多级探测器。还有其他的研究解决这个问题,通过设计更好的损失函数而不改变模型的体系结构。PISA[18]根据IoU层次局部秩(IoU-HLR)得到的分类损失的重要性,给正样本分配不同的权重。此外,分类概率被用来重写每个正例子对回归损失的贡献,表示为分类感知回归损失。对分类和回归损失的改善都能提高分类得分与定位精度的相关性。类似地,IoU均衡分类损失[19]使用回归IoU直接对每个正样本的分类损失进行重新加权,目的是使IoU较高的样本学习较高的分类得分,从而增强分类得分与定位精度之间的相关性。基于IoU的单级目标检测旨在通过设计IoU预测头来预测每个回归锚的IoU,从而改进单级目标检测。
精确的目标定位。在诸如COCO数据集这样的复杂场景中,精确的目标定位是一项极具挑战性的工作,近年来人们提出了大量的方法来提高目标检测模型的定位精度。多区域检测器[20]发现单阶段回归对于精确定位是有限的,因此提出了一种迭代包围盒回归方法来细化检测到的盒子的坐标,然后是NMS和盒子投票。Cascade R-CNN[8]提出了一种多阶段的目标检测体系结构,该结构通过提高IoU阈值来训练R-CNN序列。因此,训练后的序列R-CNN在推理过程中对精确定位具有更强的能力。RefineDet[4]使用两步边界回归提高了单级检测器的定位精度。锚细化模块(ARM)首先对人工设计的锚进行细化,以提高人工设计锚的定位精度,然后目标检测模块(ODM)利用这些更精确的锚进行第二步包围盒回归,从而提高最终检测的定位精度。Libra R-CNN[21]设计了平衡的L1损失,以促进训练过程中来自内部(精确样本)的回归梯度。因此,经过训练的回归分支将更有效地进行精确定位。类似地,IoUbalanced本地化损失[19]基于它们的回归IoU重新计算每个正例子的本地化损失。该方法可以降低野值梯度的权重,提高内点梯度的权重,从而提高模型的定位精度。不同的是,在NMS和AP计算过程中,基于计算的检测置信度,IoU感知的单级目标检测器通过抑制低定位精度的检测来提高定位精度。
无锚单级目标探测器。为了克服基于锚的检测器的缺点,无锚单级目标检测器近年来越来越流行。FCOS[22]以基于完全卷积中性网络的每像素预测方式解决对象检测问题。FCOS由三个预测头组成:用于分类的分类头、用于定位的回归头、用于预测每个检测盒中心度的中心度头。在推理过程中,将每个检测盒的预测中心度乘以相应的分类得分作为最终得分,用于后续的NMS和AP计算,以抑制局部性差的检测。PolarMask[23]通过修改FCOS来实现实例分割。同样,中心头也被用来抑制低定位精度的分割,提高模型的定位精度。基于IoU感知的单级目标检测器设计了一个与回归头平行的IoU预测头来预测每一次检测的IoU,预测的IoU可以用来抑制局部性差的检测。不同的是,IoUaware单级目标检测器是一种基于锚的检测器,预测每个检测盒的IoU。
3. Method
在这一部分中,我们将详细介绍IoU感知的单级目标检测器的模型结构和不同的设计选择。
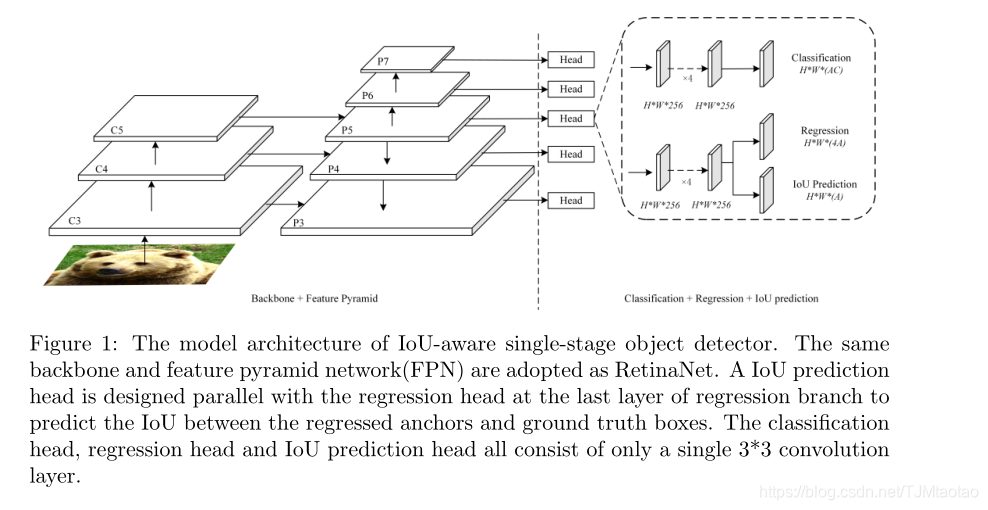
图1:IoU感知单级目标检测器的模型结构。采用与RetinaNet相同的骨干网和特征金字塔网络(FPN)。在回归分支的最后一层,设计了与回归头平行的IoU预测头,对回归锚与地面真值盒之间的IoU进行预测。分类头、回归头和IoU预测头均由单个3×3卷积层组成。
3.1. IoU-aware single-stage object detector
模型架构。IoU感知的单级目标检测器主要基于RetinaNet[3],采用与图1相同的骨干和特征金字塔网络(FPN)。与RetinaNet不同,我们设计了一个与回归分支最后一层回归头平行的IoU预测头,在保持分类分支不变的情况下,预测每个回归锚与地面真值盒之间的IoU。为了保持模型的有效性,IoU预测头只包含一个3×3卷积层,然后是一个sigmoid激活层,确保预测IoU在[0,1]的范围内。IoU预测头的设计也有很多其他的选择,例如设计一个独立的IoU预测分支,与分类分支和回归分支一样,但是这种设计会严重影响模型的效率。我们的设计给整个模型带来了很小的计算负担,并且仍然可以大大提高模型的AP。
训练。与RetinaNet一样,分类损失采用focal loss,回归损失采用平滑L1损失,如等式1,2所示。由于预测的IoU在[0,1]范围内,所以采用二元交叉熵损失作为IoU预测损失,如等式3所示。训练过程中,IoU预测头与分类头、回归头共同训练。还可以考虑其他类型的损耗函数,如L2损耗和L1损耗。在下面的实验中将比较这些不同的损耗函数。
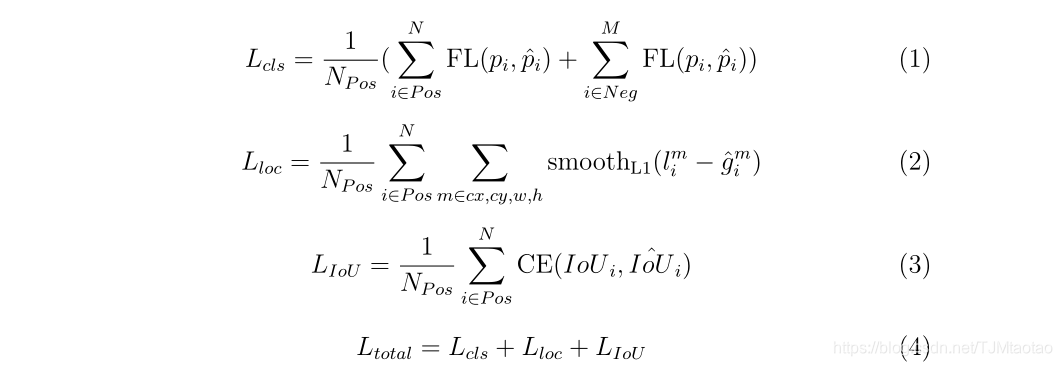
推断。在推断时,每个检测框的分类得分和预测IoU是基于eq.5作为最终检测置信度计算的。参数α用于控制分类得分和预测IoU对最终检测置信度的贡献。这种检测置信度可以同时表示分类置信度和定位精度。因此,与分类得分相比,检测置信度与定位精度的相关性更强。然后利用检测置信度对后续NMS和AP计算中的所有检测进行排序。在这个过程中,将抑制不好的局部检测。

4. Experiments
数据集和评估指标。大多数实验都是在具有挑战性的MS-COCO[24]数据集上进行评估的。它由118k张培训用图片(train-2017)、5k张验证用图片(val-2017)和20k张未公开测试标签的图片(test dev)组成。数据集中存在80个类别的500多个注释对象实例。为了证明该方法的泛化能力,我们还对消融研究中的PASCAL-VOC[25]数据集进行了实验。VOC2007由5011个训练图像(VOC2007 trainval)和4952个测试图像(VOC2007 7 test)组成。VOC2012包括17125张训练图像(VOC2012 trainval)和5138张测试图像(VOC2012 test)。所有实验均采用标准COCO式平均精度(AP)指标,由AP(IoU平均AP为0.5~0.95,区间为0.05)、AP50(IoU平均AP为0.5)、AP75(IoU平均AP为0.75)、APS(小尺度目标AP)、APM(中尺度目标AP)和APL(大尺度目标AP)组成比例尺)。
实施细节。所有的目标检测模型都是基于PyTorch和MMDetection实现的[26]。由于只有2个GPU可用,因此在训练期间采用线性缩放规则[27]来调整学习率。对于主要结果,所有模型都在COCO testdev上进行了评估。以MMDetection提供的收敛模型作为基线。在MMDetection的默认设置下,IoU感知的单级目标检测器都被训练为总共12个阶段,图像比例为[800,1333]。一些文献报道了在总时间延长1.5倍、尺度抖动的情况下对模型进行训练的主要结果。我们的实验没有采用这些技巧。在消融研究中,以ResNet50为骨干的IoU感知单级目标探测器在COCO train-2017上进行训练,并在COCO val-2017上使用图像尺度[600,1000]进行评估。对于PASCAL-VOC实验,分别在VOC2007-trainval和VOC2012-trainval上训练不同骨干的模型,并在VOC2007实验中进行评价,图像尺度为[600,1000]。如果未指定,则所有其他设置将保持与MMDdetection中的默认设置相同。
4.2. Main Results
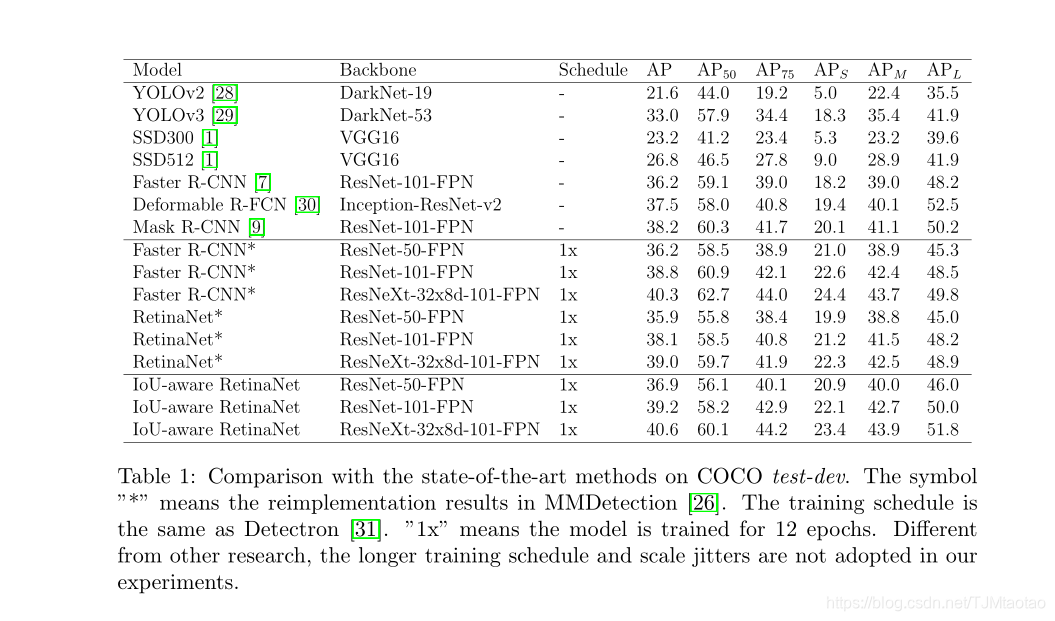
在表1所示的主要结果中,将具有不同主干的IoU感知的单级目标检测器的性能与COCO测试设备上最新的目标检测模型进行了比较。为了公平比较,将具有不同主干的MMDetectioin[26]提供的训练模型作为基线进行评估。如表1所示,与基线相比,具有不同主干的IoUaware视网膜网可显著改善AP 1.0%∼1.6%。AP50的性能略有提高或降低,但AP75的性能却有1.7%∼2.3%的大幅度提高,这表明IoU感知视网膜网络对提高模型定位精度的有效性。此外,IoU-aware视网膜系统的性能已经超过了两级检测器,同一主干网的R-CNN速度提高了0.3%∼0.7%,主要是由于IoU-aware RetinaNet具有较高的定位精度。
4.3. Ablation Studies
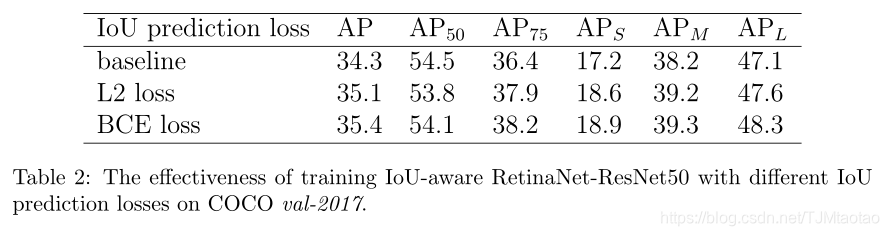
IoU预测损失。不同的IoU预测损失被用来训练IoU感知的视网膜。为了研究IoU预测损失的影响,在不使用参数α的情况下,通过直接乘以分类得分和预测IoU来计算检测置信度。如表2所示,用二元交叉熵损失训练模型比用L2损失训练模型能产生更好的性能。这可能是由于在训练具有二元交叉熵损失的IoU预测头时,预测的IoU更为准确。因此,在随后的所有实验中都采用了二元交叉熵损失。
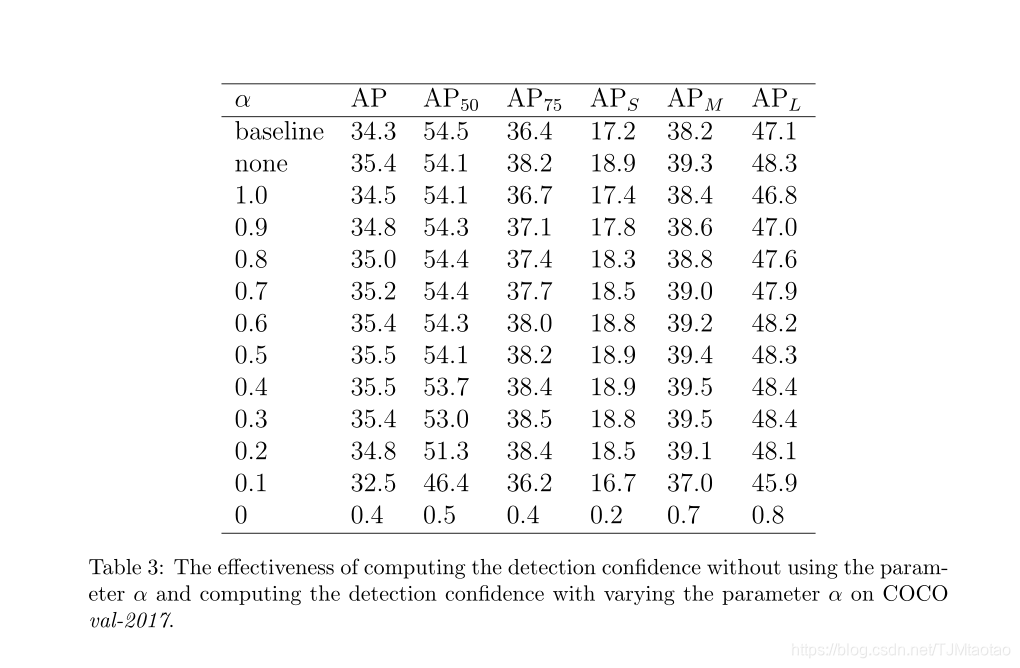
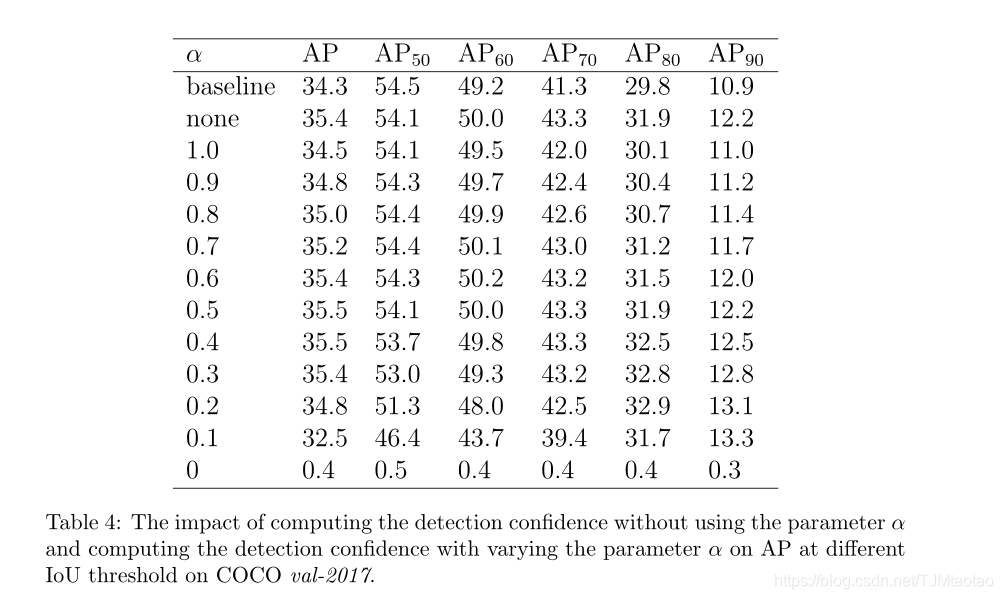
检测置信度计算。在推断时,基于Equ.5.计算检测置信度,参数α用于控制分类得分和预测IoU对最终检测置信度的贡献。从表3和表4的实验结果中可以观察到一些现象。首先,如表3所示,当α等于1.0时,仅用分类得分作为检测置信度,AP提高0.2%。这表明,具有IoU预测损失的多任务训练有利于模型的性能。其次,当α分别为0.5和0.4时,AP的最佳性能为35.5%,比基线提高1.2%。如表4所示,AP50略微降低了0.4%∼0.8%,AP70和AP80提高了2.0%∼2.7%,证明了我们的方法在提高模型定位精度方面的有效性。第三,当参数α减小以提高预测IoU对检测置信度的贡献时,AP50减小,而AP70和AP80增大,如表4所示。这表明,预测的IoU与定位精度有很强的相关性,可以使模型偏向于定位精度较高的检测。此外,检测置信度也可以通过直接乘以分类得分和预测IoU来计算,而无需使用参数α。如表3所示,在不使用参数α的情况下直接乘以分类得分和预测IoU,AP可提高1.1%,这略低于使用参数α计算检测置信度。因此,我们选择基于Equ.5.计算检测置信度。
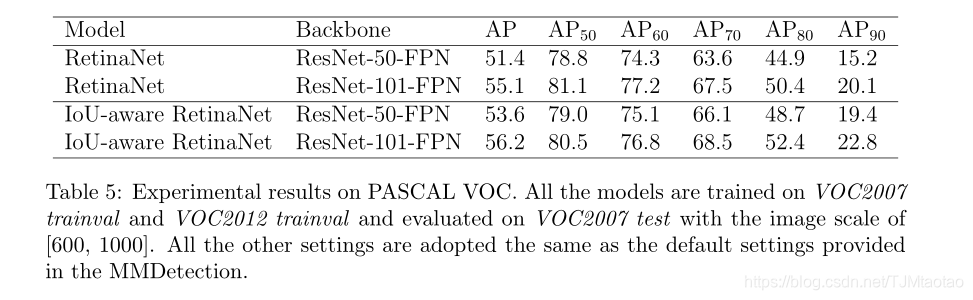
PASCAL-VOC的消融研究。如表5所示,与基线相比,IoU感知视网膜网能改善AP 1.1%∼2.2%。此外,在较高的IoU阈值(0.7,0.8,0.9)下,AP的改进率为1.0%∼4.2%,表明我们的方法可以显著提高模型的定位精度11。PASCAL-VOC数据集实验中的观测结果与COCO数据集实验中的观测结果一致,说明该方法对其他数据集具有泛化能力,可应用于不同的应用场景。
5. Conclusions
在本文中,我们证明了单级目标检测器的分类分数和定位精度之间的低相关性会严重影响模型的定位精度。因此,通过在回归分支的最后一层增加一个IoU预测头来设计IoU感知的单级目标检测器,以预测每个回归锚与地面真值盒之间的IoU。这样,模型就可以知道每次检测的定位精度。在推理时,通过将分类分数和预测IoU相乘来计算检测置信度,然后在随后的NMS和AP计算中用于对所有检测进行排序。在MS-COCO数据集和PASCAL-VOC数据集上的大量实验表明,基于IoU的单级目标检测方法可以显著提高模型的性能,尤其是定位精度。
References
[1] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, A. C.
Berg, Ssd: Single shot multibox detector, in: European conference on
computer vision, Springer, 2016, pp. 21–37.
[2] J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once:
Unified, real-time object detection, in: Proceedings of the IEEE confer-
ence on computer vision and pattern recognition, 2016, pp. 779–788.
[3] T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense
object detection, in: Proceedings of the IEEE international conference
on computer vision, 2017, pp. 2980–2988.
[4] S. Zhang, L. Wen, X. Bian, Z. Lei, S. Z. Li, Single-shot refinement neural
network for object detection, in: Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, 2018, pp. 4203–4212.
12
[5] Z. Zhang, S. Qiao, C. Xie, W. Shen, B. Wang, A. L. Yuille, Single-
shot object detection with enriched semantics, in: Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition, 2018,
pp. 5813–5821.
[6] B. Li, Y. Liu, X. Wang, Gradient harmonized single-stage detector,
in: Proceedings of the AAAI Conference on Artificial Intelligence, vol-
ume 33, 2019, pp. 8577–8584.
[7] S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time
object detection with region proposal networks, in: Advances in neural
information processing systems, 2015, pp. 91–99.
[8] Z. Cai, N. Vasconcelos, Cascade r-cnn: Delving into high quality object
detection, in: Proceedings of the IEEE conference on computer vision
and pattern recognition, 2018, pp. 6154–6162.
[9] K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask r-cnn, in: Proceedings
of the IEEE international conference on computer vision, 2017, pp. 2961–
2969.
[10] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie,
Feature pyramid networks for object detection, in: Proceedings of the
IEEE conference on computer vision and pattern recognition, 2017, pp.
2117–2125.
[11] J. Dai, Y. Li, K. He, J. Sun, R-fcn: Object detection via region-based
fully convolutional networks, in: Advances in neural information pro-
cessing systems, 2016, pp. 379–387.
[12] R. Girshick, Fast r-cnn, in: Proceedings of the IEEE international
conference on computer vision, 2015, pp. 1440–1448.
[13] R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies
for accurate object detection and semantic segmentation, in: Proceed-
ings of the IEEE conference on computer vision and pattern recognition,
2014, pp. 580–587.
[14] L. Tychsen-Smith, L. Petersson, Improving object localization with fit-
ness nms and bounded iou loss, in: Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, 2018, pp. 6877–6885.
13
[15] L. Tychsen-Smith, L. Petersson, Denet: Scalable real-time object de-
tection with directed sparse sampling, in: Proceedings of the IEEE
International Conference on Computer Vision, 2017, pp. 428–436.
[16] B. Jiang, R. Luo, J. Mao, T. Xiao, Y. Jiang, Acquisition of localiza-
tion confidence for accurate object detection, in: Proceedings of the
European Conference on Computer Vision (ECCV), 2018, pp. 784–799.
[17] Z. Huang, L. Huang, Y. Gong, C. Huang, X. Wang, Mask scoring r-
cnn, in: Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition, 2019, pp. 6409–6418.
[18] Y. Cao, K. Chen, C. C. Loy, D. Lin, Prime sample attention in object
detection, arXiv preprint arXiv:1904.04821 (2019).
[19] S. Wu, X. Li, IoU-balanced Loss Functions for Single-stage Object De-
tection, arXiv e-prints (2019) arXiv:1908.05641. arXiv:1908.05641.
[20] S. Gidaris, N. Komodakis, Object detection via a multi-region and
semantic segmentation-aware cnn model, in: Proceedings of the IEEE
international conference on computer vision, 2015, pp. 1134–1142.
[21] J. Pang, K. Chen, J. Shi, H. Feng, W. Ouyang, D. Lin, Libra r-cnn:
Towards balanced learning for object detection, in: Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition, 2019,
pp. 821–830.
[22] Z. Tian, C. Shen, H. Chen, T. He, FCOS: Fully Convolutional
One-Stage Object Detection, arXiv e-prints (2019) arXiv:1904.01355.
arXiv:1904.01355.
[23] E. Xie, P. Sun, X. Song, W. Wang, X. Liu, D. Liang, C. Shen, P. Luo,
PolarMask: Single Shot Instance Segmentation with Polar Representa-
tion, arXiv e-prints (2019) arXiv:1909.13226. arXiv:1909.13226.
[24] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,
P. Doll´ ar, C. L. Zitnick, Microsoft coco: Common objects in context,
in: European conference on computer vision, Springer, 2014, pp. 740–
755.
14
[25] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, A. Zisserman,
The pascal visual object classes (voc) challenge, International journal
of computer vision 88 (2010) 303–338.
[26] K. Chen, J. Wang, J. Pang, Y. Cao, Y. Xiong, X. Li, S. Sun, W. Feng,
Z. Liu, J. Xu, et al., Mmdetection: Open mmlab detection toolbox and
benchmark, arXiv preprint arXiv:1906.07155 (2019).
[27] P. Goyal, P. Doll´ ar, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola,
A. Tulloch, Y. Jia, K. He, Accurate, large minibatch sgd: Training
imagenet in 1 hour, arXiv preprint arXiv:1706.02677 (2017).
[28] J. Redmon, A. Farhadi, Yolo9000: better, faster, stronger, in: Proceed-
ings of the IEEE conference on computer vision and pattern recognition,
2017, pp. 7263–7271.
[29] J. Redmon, A. Farhadi, Yolov3: An incremental improvement, arXiv
preprint arXiv:1804.02767 (2018).
[30] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, Y. Wei, Deformable
convolutional networks, in: Proceedings of the IEEE international con-
ference on computer vision, 2017, pp. 764–773.
[31] R. Girshick, I. Radosavovic, G. Gkioxari, P. Doll´ ar, K. He, Detectron,
https://github.com/facebookresearch/detectron, 2018.

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)