
产品新说 | 智能运维告警的智能聚类、压缩及降噪
伴随着数字化转型的迫切需求,企业的IT架构随着对业务和用户体验的需求增加而变得越来越庞大,跨云部署使运维工作变得更加复杂。当业务出现异常波动时会产生海量的告警信息,使得运维工程师对告警信息的甄别及处理面临着巨大的挑战。本文将和大家分享告警噪音产生的原因,擎创告警压缩降噪的两阶段方法论和擎创产品针对告警噪音的解决方案。
导读
伴随着数字化转型的迫切需求,企业的IT架构也经历了从C/S架构,迁移到B/S架构,移动化的兴起再转移到移动APP和小程序,再加上云计算、物联网、边缘计算等新技术的应用,使企业的IT架构随着对业务和用户体验的需求增加而变得越来越庞大,跨数据吣、跨云部署使运维工作变得更加复杂。当业务出现异常波动时,我们所依赖的这些数字化组件会产生海量的告警信息,使得运维工程师对告警信息的甄别及处理面临着巨大的挑战。
本文将和大家分享擎创告警辨析中心产品在数字化转型浪潮下如何帮助企业直面告警噪音,主要包括以下几大方面的内容:
-
告警噪音产生的原因
-
擎创告警压缩降噪的两阶段方法论
-
擎创产品针对告警噪音的解决方案
No.1
告警产生的原因
数据中心产生告警噪音,一般由两个大的原因所引起,我们了解这些原因的特征之后,可以通过有针对性的解决方案来解决这些问题。
第一个原因,存在大量重复的告警:大多数监控系统关注的点在快速、无遗漏地将异常告警抛出,如:
-
网络监控的告警,某一网络设备一分钟内网络设备的闪断会报三次。
-
业务监控的告警,同一个业务系统10分钟发生的交易量异常而报5次。
-
...
第二个原因,大量的告警因为服务组件之间的相互依赖关系、相互影响,而产生的大量的关联告警:
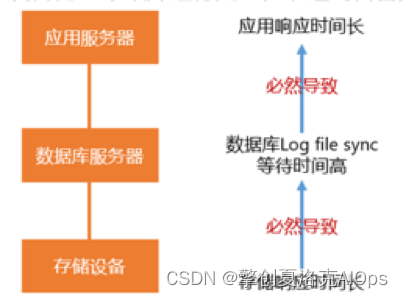
如上图所示,由于存储设备的存储响应时间长,导致了数据库服务器的log file sync等待时间长告警和应用服务器的响应时间长告警。
-
由于网络设备的故障,导致用该网络的所有主机都产生告警。
-
数据库集群的主机出现CPU高负载的告警。
-
...
No.2
擎创告警压缩降噪的两阶段方法论
通过对告警噪音产生原因的特征识别,我们提出了两阶段处理的方法论,即:告警压缩降噪 = 告警去重 + 告警关联。
告警去重:将同一个监控源、同一告警对象、同一指标在单位时间内产生的多次源监控系统的原始告警进行去重并压缩成同一个告警,这个阶段要考虑如下问题:
-
针对不同的监控场景(如网络设备、应用监控等),单位时间该如何设置才是有效的?这就要求针对不同的监控场景可参数化配置时间段。
-
如何有效识别同一告警对象,如对主机的监控好多企业都配置的是监控某个IP地址,但是在不同的网络区域和不同的数据中心中,IP地址可能是重复的,尤其是将所有数据中心的告警统一上收到统一告警平台后,这些告警因为去重策略的不当而造成不同数据中心不同主机的告警会压缩到一起。
-
同一设备的指标唯一性识别问题,如果监控系统只是在告警描述中存在这些信息,而没有独立的字段来区分,也不能够达到很好去重目的,这就要求告警辨析中心要能够通过多种方式进行处理:
-
通过正则匹配等技术对告警内容取告警指标、告警对象等信息并补充到告警字段中,以备后续使用
-
要求源监控系统补充这些关键字段内容
-
通过智能化手段对告警文本聚类,并生成聚类模板来完成告警去重
-
...
02
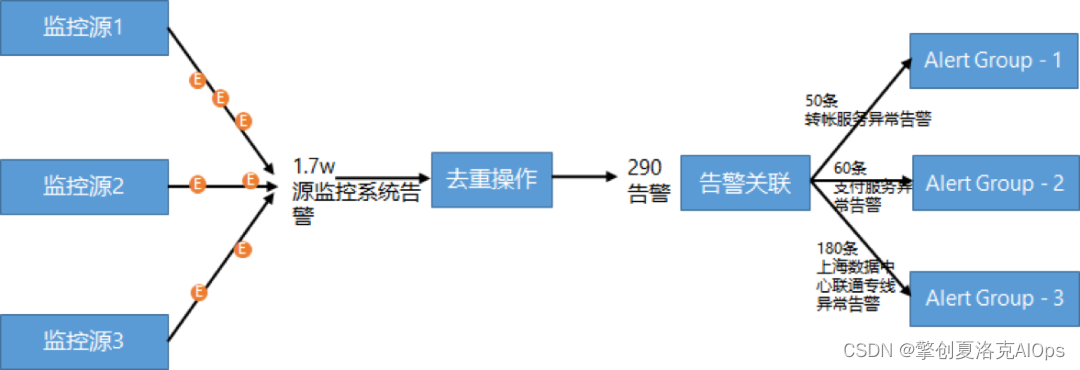
告警关联:告警关联有一个事实上的理论依据,即同一个业务或服务的各种技术组件,甚至技术组件内部的监控指标之间实际上是高度相关的,一个指标的告警可能会导致相关组件的指标发生异常,有经验的领域专家是知道其不同技术组件的时序指标的相关性的,由于描述的都是同一个问题所引起的告警,因此我们可以对其进行告警关联合并为一个alert Group进行处理,以达到进一步压缩降噪之目的,并实现业务的全面可观测性,如下图所示:
针对告警的关联,同时也有很多的条件限制,需要解决:
-
领域专家经验:针对告警关联,需要比较强的领域专家经验,目前大多数的企业很难拿出这样的领域经验来将告警进行关联。
-
数据质量问题:如何有效识别告警对象以及告警对象之间的依赖关系,进行关联的数据基础。
-
如何有效识别同一告警对象,如对主机的监控好多企业都配置的是监控某个IP地址,但是在不同的网络区域和不同的数据中心中,IP地址可能是重复的,尤其是将所有数据中心的告警统一上收到统一告警平台后,这些告警因为关联策略的不当而造成不同数据中心不同主机的告警会关联到一起。
-
...
No.3
擎创产品针对告警噪音的解决方案
擎创告警辨析中心4.0产品是擎创研发的新一代智能告警管理、分析及处置平台,该平台分为监、管、控三个核心部分,同时在各个部分又体现了其分析和智能化能力,如下图所示。
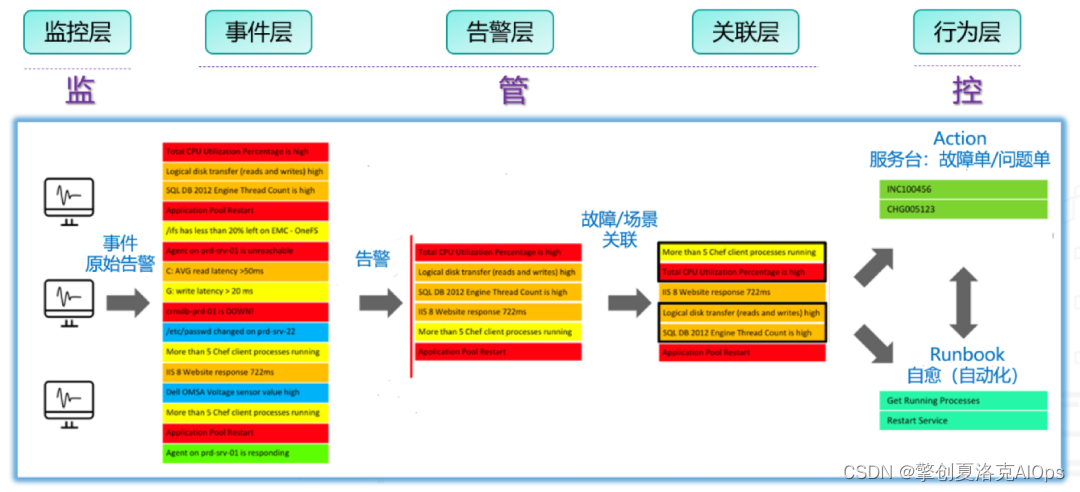
监 - 源监控系统层
源监控系统层,即企业已有的监控系统平台,如APM、NPM、Zabbix、Prometheus等企业自建的监控工具,主要用于对数据中心、云环境下不同的应用、网络设备、主机、数据库、存储设备、机房环境等进行监控,以获取原始告警事件。并发送到擎创告警辨析中心产品,以实现对企业所有业务的动态感知及全面可观测性。
管 - 即擎创的告警辨析中心
在擎创的告警辨析中心,我们主要完成:
-
接入管理:源监控系统层的告警数据接入管理
-
数据质量问题:如原始告警治理:对接入的原始告警进行丰富及标准化处理何有效识别告警对象以及告警对象之间的依赖关系,进行关联的数据基础。
-
智能去重:针对丰富及标准化处理后的原始告警进行智能去重,生成可操作的告警
-
智能关联分组:针对生成的告警进行智能化关联,对告警进行分组管理,便于企业运维人员进行故障分析及修复
-
另外还包括:告警通知、根因分析、告警360视图、告警协作分析等能力,非本文重点,在此不再介绍。
“管” 之 “ 接入管理”
接入管理完成对源监控系统层数据接入,包括原始告警、变更等相关的事件,可支持API、KAFKA、SNMP、socket等不同传输协议的源监控系统层告警信息的接入。
下图是目前已经支持的源监控系统层的接入配置,后续会增加对市场主流的监控工具之集成支持,使运维管理人员可以经过简单的配置即可将源监控系统以及相关的告警和变更事件轻松集成到告警辨析中心。

“管” 之 “ 原始告警治理”
将源监控系统所产生的告警接入之后,第二步操作即实现原始告警治理 。原始告警治理是后续进行告警的智能压缩及降噪的数据基础,甚至在后续进行可视化分析、根因定位、故障自愈都离不开的基础操作。
产品支持从企业现有CMDB的数据库定时批量或手工导入外部的基础数据或其它的非CMDB数据(如配置项对应的管理人员或群组信息),通过动态建立数据关联关系查询的方式来进原始的告警信息进行数据丰富、标准化治理工作。
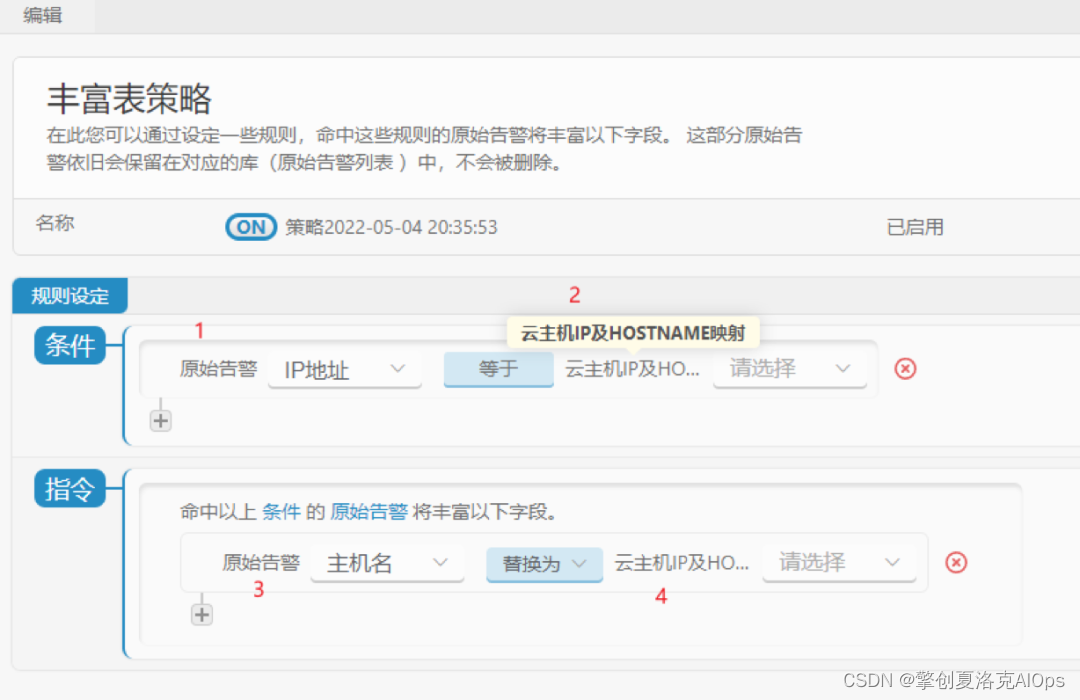
通过批量、API、手工导入的外部丰富数据及擎创告警产品提供的丰富表策略来对告警信息进行丰富处理,如上图所示我们将云管理平台的“云主机IP及HOSTNAME映射”关系每小时同步给擎创告警辨析中心,告警辨析中心接收到告警之后通过IP地址到“云主机IP及HOSTNAME映射”中动态查询故障时点云主机IP地址所对应的真实主机名称(CMDB中唯的配置项ID),以丰富到告警中,以便后续对告警进行处理。
“管” 之 “ 智能去重”
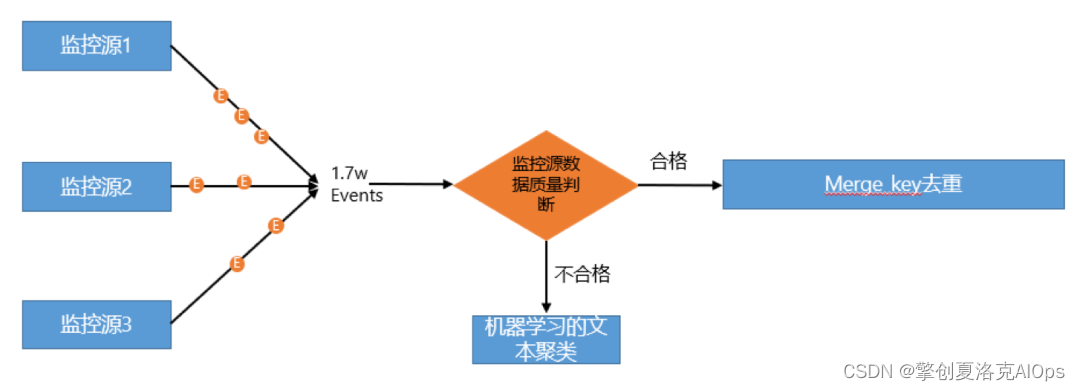
擎创的告警辨析中心产生智能去重,包括两种方式:
-
通过merge_key去重:对监控源产品的告警进行质量判断,如果合格通知生成merge_key则通过merge_key加告警的时间段滑动窗口来进行去重。这一般比较适用于企业的IT监控系统数据质量治理比较好的企业。
-
通过对告警内容进行基于机器学习的文本聚类去重:如果对监控源产品的告警质量判断不合格,则对告警所产生的“告警描述”的文本字段内容,通过基于机器学习的文本聚类方法来对告警进行聚类,并生成相应的聚类模板,相同聚类模板ID的告警加告警的时间段滑动窗口来进行去重。
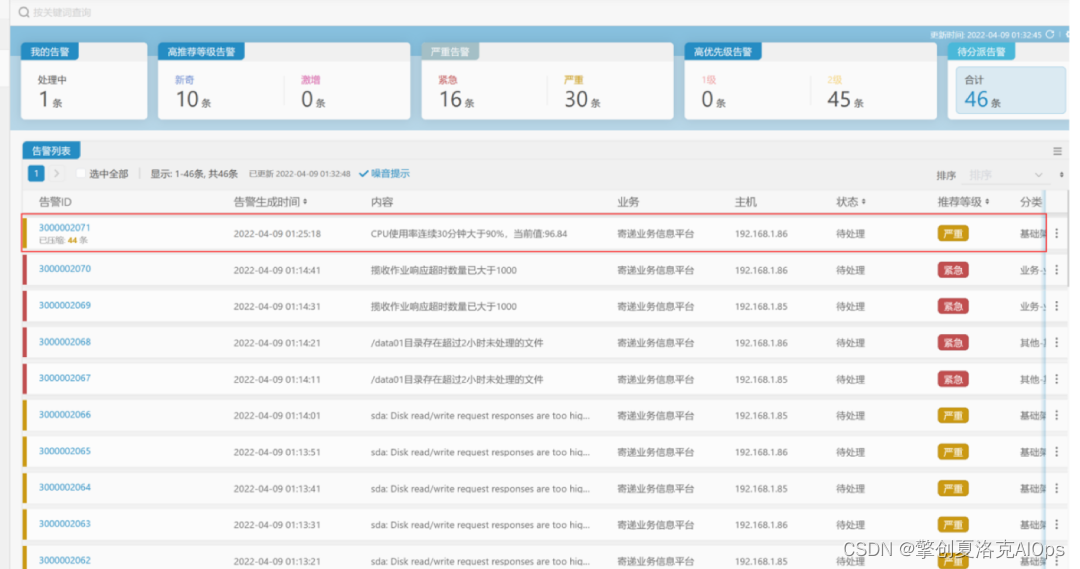
如下图所示,可以看到去重压缩之后的告警列表信息:
“管” 之 “ 智能关联分组”
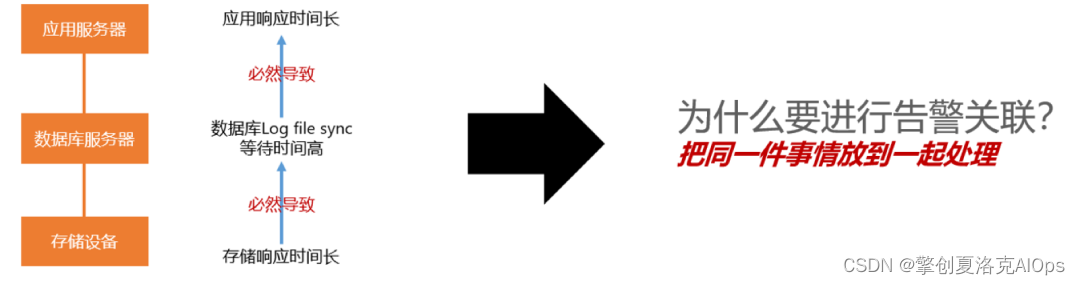
上文提到了我们进行告警关联的核心思想是将同一件事情放到一起处理,这里我们对同一件事情进行解释说明,如在IT架构中,因为组件B的问题导致A产生问题,在一段时间内A产生问题后又导致C和D产生问题,则会将BACD关联到一起进行处理。

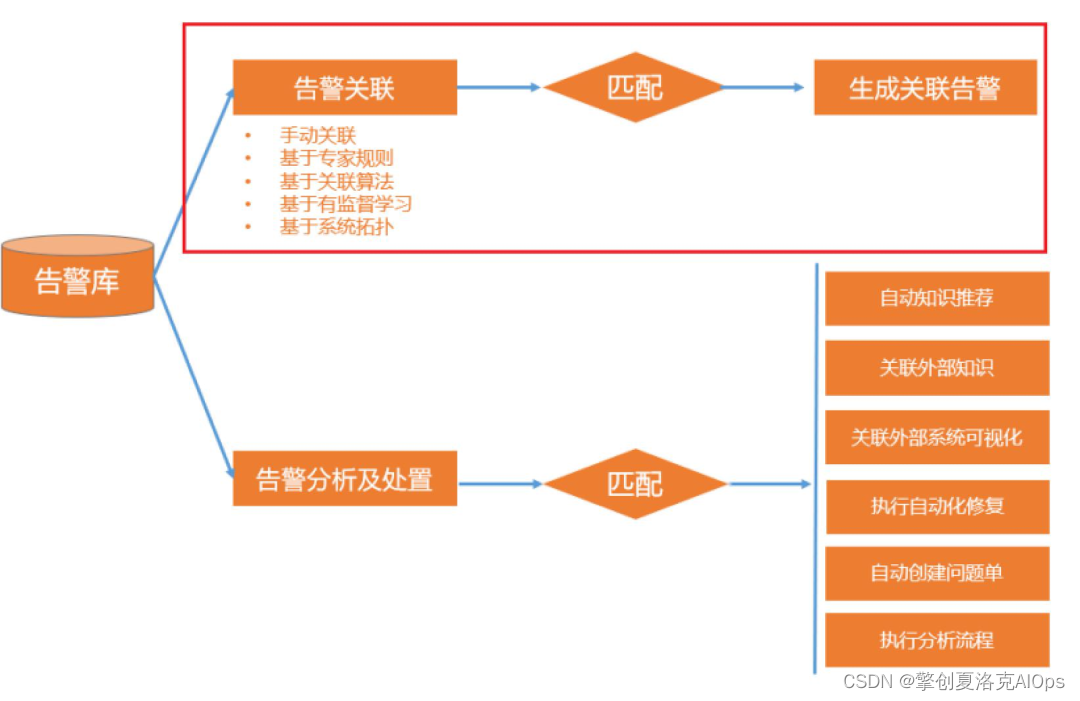
擎创辨析中心产品的告警关联分组,如下图所示,支持5种关联方案:
-
手动关联:在多个告警同时发生的情况下,不同的团队成员需要对多个告警进行分别处理,而团队成员在相互沟通的情况下,认为某几个告警在该段时间范围内发生是有关联关系的,因此将这几个告警进行手动关联并统一进行处理。
-
基于专家规则:系统的长期运行过程中,某些运维领域专家会发现一些常出现的问题,并整理成专家规则,如存储设备的响应时间变长必然会导致依赖存储的ORACLE数据库服务出现Log file sync等待时间高问题,将这些专家所总结的场景,我们会在系统中规则化,碰到满足条件的则会关联到一起进行处理。
-
基于AI的关联算法:企业中的领域专家也比较难以对动态化(变更以及组件的改变和升级所引起)的且越来越复杂的IT架构进行专家规则化处理,擎创独有的针对数据中心时序告警数据进行关联分析组件,可以帮助运维领域专家发现组件之间时序变化模式,并将捕捉到的模式提供给专家进行审核并将符合条件的模式一键发布至告警辨析中心使用。
-
基于AI的有监督学习算法:针对运维领域专家手动关联的告警,会定期进行自动化的机器学习,伴随着系统的持续稳定运行,其学习到效果会越来越准确。
-
基于系统拓扑关联:针对未能进行关联匹配的告警,可以进行基于系统的拓扑关联,该方式会更普适化,如:将5分钟范围内所产生的同一集群的DB主机告警关联到一起进行处理
控 - 智能建单及智能自愈
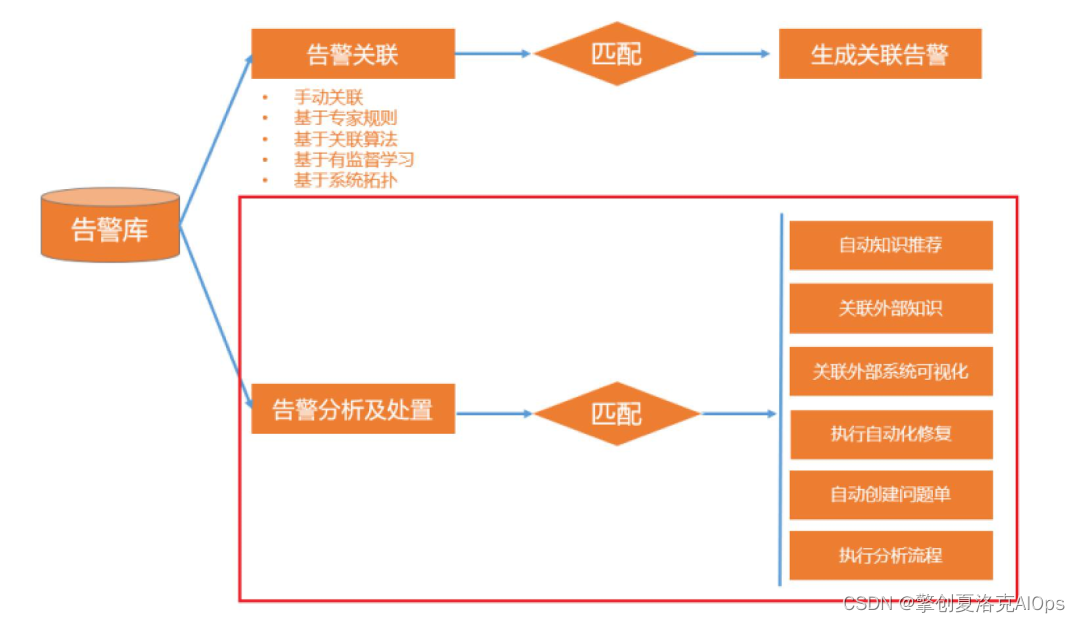
擎创告警辨析中心产品的“控”主要体现在根据不同类型的告警或已知经常发生的告警,我们可以结合专家经验进行告警的智能分析及处置,主要包括:
-
自动知识推荐:可以根据专家规则、配置项类型、告警文本等匹配知识库中的内容并进行自动知识推荐,以方便在进行分析、处置的过程中参考相应的Runbook手册,如发生Oracle发生ORA-XXXXX 类型告警时,则自动关联ORACLERunbook厂商手册的ORA-XXXXX章节。
-
关联外部知识:一些开源组件提供了很好的社区支持,我们可以通过google等搜索工具,直接进行当前告警内容的关键字搜索,以快速查看搜索结果内容或直接通过开源社区的关键字查询能力,直接跳转到开源社区支持页面,找到相应的处理方案。
-
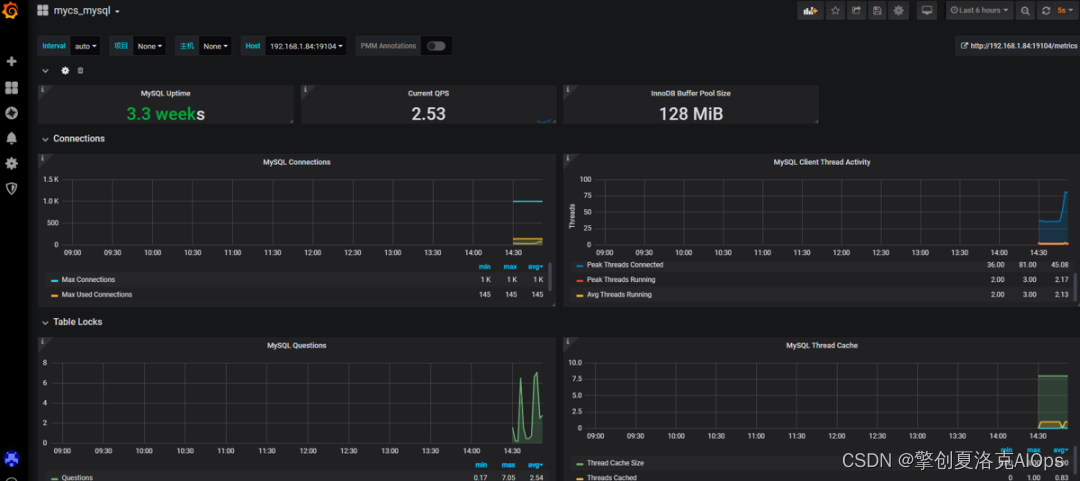
关联外部系统可视化:可以通过URL将当前告警的时间段、配置项ID、告警指标等作为参数,直接跳转到Grafana、运维数据中台等系统直接查看告警时段的指标趋势曲线。如:当主机发生某指标告警时,则我们会根据安装Grafana的部署地址自动拚接URL,并跳转到Grafana的mysql监控仪表板页面,如下图所示为提前建好的MySQL监控仪表板:
-
执行自动化修复:针对已知的问题场景,我们会通过自动化修复机制调度企业内部的自动化平台系统进行自动化修复。如:ORACLE数据库出现表空间不足异常,则自动调用表空间回收策略,以释放数据库表空间。
-
自动创建问题单:针对部分问题,我们可以通过对JIRA等工具的集成,一键创建问题工单。
-
执行分析流程:针对大型的复杂系统,在产生问题时,需要对各个组件进行排查分析,以逐步定位缩小问题范围,直到最终找到问题点并修复问题。如某大型银行的二代支付系统涉及到跨行转账业务,需要完成同银联的系统集成,因此发生问题时,需要先判断是来报异常还是往报异常,进而判断问题是银行内部,还是银联等外部机构问题造成,最终再进一步确认问题,并修复问题恢复业务。
总结
擎创告警辨析中心产品的智能压缩及降噪功能,更具智能化,不仅可以满足科技能力及数据治理较强的企业需求,同时也可以通过智能化手段满足科技及数据治理较差企业的需求。
擎创告警辨析中心产品可配置能力更成熟,具有更开放的集成能力,可以将数据中心的监控系统、ITSM流程平台系统、自动化引擎系统、知识库系统、通知类平台等系统无缝集成,并驱动整个数据中心运维体系更快、更智能、更流畅运行。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)