
【playwright】新一代自动化测试神器playwright+python系列课程59_pytest-playwright_pytest监听网络请求事件
在上述案例的on_response函数中,添加了一个判断条件,这样我们就实现了只获取响应url中包含了’/zentao/user-login.html’的响应头。方法还可以用于监听页面中的网络请求事件,包括请求发送前、请求发送后、请求成功、请求失败等等,在监听到这些事件之后,也可以执行相应的回调函数进行响应。方法可以用于在页面中监听和响应各种事件,本文主要介绍一下监听网络请求事件。我们以reque
·
pytest-playwright_监听网络请求事件
在 Playwright 中,有一个on 方法可以用于在页面中监听和响应各种事件,本文主要介绍一下监听网络请求事件。
监听网络请求事件:on 方法还可以用于监听页面中的网络请求事件,包括请求发送前、请求发送后、请求成功、请求失败等等,在监听到这些事件之后,也可以执行相应的回调函数进行响应。
本文介绍一下监听网络请求事件,每当页面发送网络资源请求时,页面都会发出以下事件序列:
page.on("request")当页面发出请求时触发
page.on("response")接收到请求的响应状态和标头时触发
page.on("requestfinished")当响应主体被下载并且请求完成时发出。
page.on("requestfailed")如果请求在某个时刻失败发出
我们以request和response为例看一下如何监听
实践代码:
# '''
# author: 测试-老姜 交流微信/QQ:349940839
# 欢迎添加微信或QQ,加入学习群共同学习交流。
# QQ交流群号:877498247
# 西安的朋友欢迎当面交流。
# '''
from playwright.sync_api import Playwright, sync_playwright, expect
import re
import pytest
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("http://127.0.0.1/zentao/user-login.html")
page.locator("#account").fill("admin")
page.locator("input[name=\"password\"]").click()
page.locator("input[name=\"password\"]").fill("Deshifuzhi01")
page.on("request", lambda request: print("request info :", request.method, request.url))
page.on("response", lambda response: print("response info :", response.status, response.url,response.text))
page.get_by_role("button", name="登录").click()
page.wait_for_timeout(10000)
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
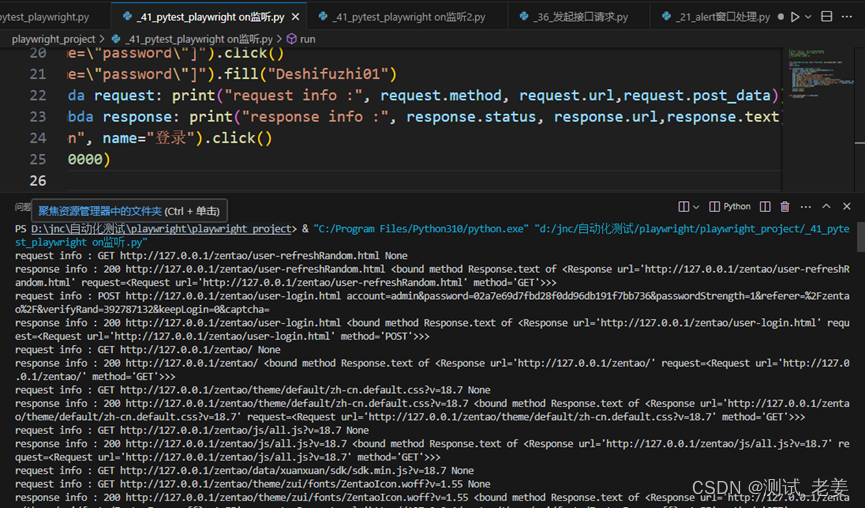
从上图中我们可以发现,page.on()监听了所有的请求和响应信息,非常多,这里面有很多是没有用的,这个时候我们可以增加判断条件,监听我们想要的请求或响应,看下面案例:
# '''
# author: 测试-老姜 交流微信/QQ:349940839
# 欢迎添加微信或QQ,加入学习群共同学习交流。
# QQ交流群号:877498247
# 西安的朋友欢迎当面交流。
# '''
from playwright.sync_api import Playwright, sync_playwright, expect
import re
import pytest
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("http://127.0.0.1/zentao/user-login.html")
page.locator("#account").fill("admin")
page.locator("input[name=\"password\"]").click()
page.locator("input[name=\"password\"]").fill("Deshifuzhi01")
def on_response(response):
if '/zentao/user-login.html' in response.url:
print(response.all_headers())
page.on("response",lambda response: on_response(response))
page.get_by_role("button", name="登录").click()
page.wait_for_timeout(10000)
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
在上述案例的on_response函数中,添加了一个判断条件,这样我们就实现了只获取响应url中包含了’/zentao/user-login.html’的响应头。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)